背景
之前有介绍过netconsole,这个模块可以把内核日志转发到远程主机上。如果在加载模块的配置转发的远程主机的端口号是rsyslog的端口号的话,其实就可以做到把本地的内核日志转发到远程的rsyslog,由rsyslog进行统一管理
在一次实验过程中进行了上面的配置,但是发现远程的主机侧由丢失log的现象发生,因此进行排查
排查
首先,需要确定一件事,本地是否发送了UDP包?远程是否收到了UDP包。这个很关键,必须先确定是本地还是远端出现的问题。
先netstat -s -u看一下本地和远端,发现远端有一些buffer size error(这块是内核缓冲区)
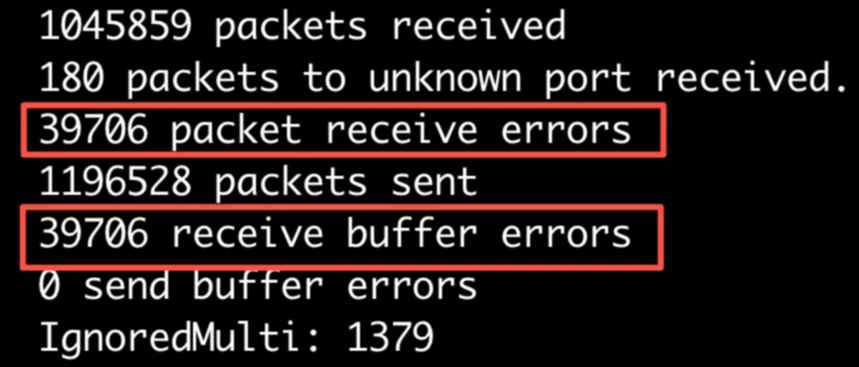
这俩数值相同,所以这块的error全是receive buffer引起的,因为buffer size不够大?
那把远端的net.core.rmem_max net.core.rmem_default和net.core.netdev_max_backlog都调大一下,还是不行(这是系统层面的)
然后把rsyslog的buffer size调大一点,再试试(这是进程层面的),再测试就没有上面的error了,所以这个可以通过调大buffer size的大小来缓解

但是,还没完,虽然没有error了,但是还是缺少很多log,说明这个虽然可能缓解这个问题,但是不只导致丢log的根源,需要继续排查
尝试tcpdump抓包看一下包是丢在哪里的,这块有个问题需要澄清一下,之前没有注意到,在本地使用tcpdump是抓不到包的,为什么呢?可以看之前讲的netpoll原理,他其实就直接从驱动侧把包发出去了,不走网络协议栈。
但是远端是可以抓这些包的,因为它收到包之后会走协议栈。
tcpdump -i eth0 udp and src host XXX and dst port 514 -w output.pcap
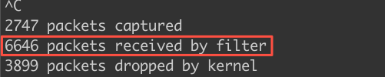
可以看到远端只收到了6646个包,而本地应该发多少包呢?可以直接dmesg看一下有多少条消息,别忘了这是在调试netconsole丢日志,而netconsole是转发的内核日志。看了下dmesg中有65536条数据。
那还得确定一个内容,就是本地dmesg有65536条消息,是不是就意味着发了65536个UDP包呢?
之前已经分析,往netconsole发消息其实就是调用netconsole这个console设备的wirte函数来写,也就是wirte_msg,因此ftrace一下,没发现什么线索
接下来bpftrace抓一下本地netpoll_send_skb这个函数,这个是真正的向卡侧发包的函数
kprobe:netpoll_send_skb
{
$skb = arg1;
$len = *(uint32 *)($skb + 0x70);
printf("netpoll_send_skb: skb->len = %d\n", $len);
}
这个获取len的方法如下
//netpoll_send_skb的函数参数如下,在skb中存储着这个msg的长度
netdev_tx_t netpoll_send_skb(struct netpoll *np, struct sk_buff *skb)
{
unsigned long flags;
netdev_tx_t ret;
...
//skb结构体定义如下,我们要找的就是最后的那个len数据
//因此,需要根据这个结构体内容算出它的偏移,当然了,不好算的话搞一个core或者kcore直接打印一下也可以
struct sk_buff {
union {
struct {
/* These two members must be first to match sk_buff_head. */
struct sk_buff *next;
struct sk_buff *prev;
union {
struct net_device *dev;
/* Some protocols might use this space to store information,
* while device pointer would be NULL.
* UDP receive path is one user.
*/
unsigned long dev_scratch;
};
};
struct rb_node rbnode; /* used in netem, ip4 defrag, and tcp stack */
struct list_head list;
struct llist_node ll_node;
};
union {
struct sock *sk;
int ip_defrag_offset;
};
union {
ktime_t tstamp;
u64 skb_mstamp_ns; /* earliest departure time */
};
/*
* This is the control buffer. It is free to use for every
* layer. Please put your private variables there. If you
* want to keep them across layers you have to do a skb_clone()
* first. This is owned by whoever has the skb queued ATM.
*/
char cb[48] __aligned(8);
union {
struct {
unsigned long _skb_refdst;
void (*destructor)(struct sk_buff *skb);
};
struct list_head tcp_tsorted_anchor;
#ifdef CONFIG_NET_SOCK_MSG
unsigned long _sk_redir;
#endif
};
#if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
unsigned long _nfct;
#endif
unsigned int len,
data_len;
发现bpftrace抓到的包长度和远端tcpdump抓到的包的长度是可以对应上的,这就说明本地抓netpoll_send_skb抓对了,确实是通过这个函数发送的
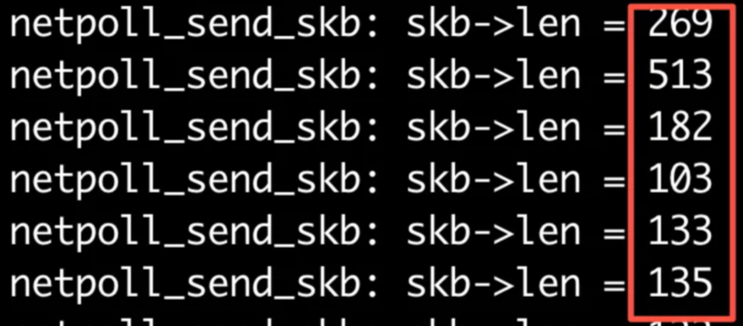
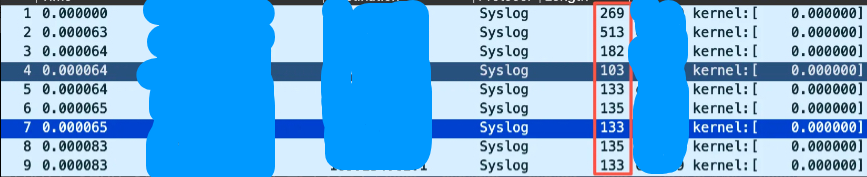
那接下来就看看在本地调用了多少次netpoll_send_skb函数呢?这个是不是能和dmesg的输出对应上呢?经过检查,这两个数字差不多是能对应上的,所以这个就可以说明,内核的日志通过netconsole转发的时候是走netpoll_send_skb的,而且基本是每一行日志都调用了一次netpoll_send_skb
再继续向后分析,看看netpoll_send_skb函数内容,又ftrace了一下dev_kfree_skb_irq,发现没有调用到这个函数,说明都正常到__netpoll_send_skb中去了
netdev_tx_t netpoll_send_skb(struct netpoll *np, struct sk_buff *skb)
{
unsigned long flags;
netdev_tx_t ret;
if (unlikely(!np)) {
dev_kfree_skb_irq(skb);
ret = NET_XMIT_DROP;
} else {
local_irq_save(flags);
ret = __netpoll_send_skb(np, skb);
local_irq_restore(flags);
}
return ret;
}
再ifconfig看一下,确认这些包是在发送端被丢掉了(PS:其实早该先查看这个的,那就基本不需要前面的证明了,这一个内容差不多就可以证明是发送端的问题了)
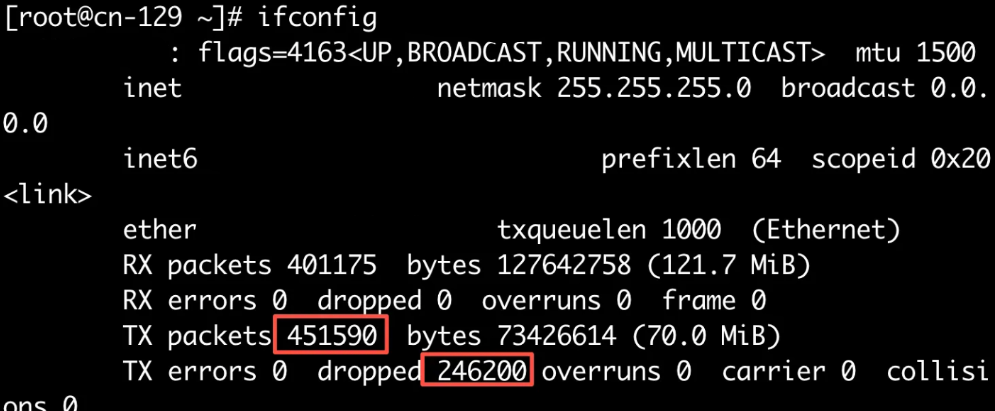
安装dropwatch看一下,这个可以查看丢包发生的函数
[root@XXX ~]# dropwatch -l kas
Initalizing kallsyms db
dropwatch> start
Enabling monitoring...
Kernel monitoring activated.
Issue Ctrl-C to stop monitoring
4816 drops at __init_scratch_end+2824470d (0xffffffffc084470d)
6 drops at netlink_broadcast+308 (0xffffffff95ceebd8)
3 drops at tcp_v4_rcv+82 (0xffffffff95d46482)
5 drops at unix_stream_connect+2bf (0xffffffff95db2f7f)
1 drops at tcp_rcv_state_process+f7 (0xffffffff95d37ee7)
^CGot a stop message
dropwatch>
可以发现大多数丢在了0xffffffffc084470d,看了下这块也不知道是干什么的。crash一下/proc/kcore看了一下,没什么发现
还好我用的6系内核已经实现了drop reason,可以查看丢包原因了,这就简单多了,直接trace一下kfree_skb_reason,它的第二个参数就是drop_reason
#!/usr/bin/env bpftrace
kprobe:kfree_skb_reason
{
$reason =(uint64 *)arg1;
printf("reason %d\n", $reason);
}
trace结果发现,大部分drop reason是55,这个数量也基本符合上面的排查
[root@XXX~]# cat bbb |grep 55|wc -l 4183
到内核中查一下这个enum的skb_drop_reason中55代表什么呢?SKB_DROP_REASON_FULL_RING
ring buff满了,调整一下网卡的缓冲区大小,解决
其实这个如果不是因为网卡是模拟出来的没法使用ethtool -S XXX查看的话,应该早就可以定位到了
后记
如果怀疑是缓冲区满了导致的丢包,可以尝试调大三个内容:
1.网卡队列深度,这个一般通过ethtool -S可以看到是不是在网卡层面丢包
2.内核缓冲区大小,可以通过调整net.core.rmem_max net.core.rmem_default、net.core.netdev_max_backlog这些内核参数来改变
3.进程的缓冲区大小。这个就需要根据特定的进程或服务来修改了
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 857879363@qq.com