背景
有时候,会发现虚机中的偶数核的cpu利用率比奇数核要高
排查
这里的排查过程就省略了,主要就是怀疑中断绑核核RPS XPS的问题,不过经过排查,不是这些问题
这时候就该想到cfs调度器本身的问题上了
学习一下sched_domain相关的内容
学习
首先sched_domain与什么有关呢?负载均衡。为什么出现sched_domain?也是因为负载均衡的需要,因为现在的CPU拓扑是有些复杂的,可能涉及numa socket die HT等内容,而一个任务往其他cpu上调度的cost与性能影响也与拓扑有关,比如任务从一个cpu迁移到同core中的CPU上(也就是一个core中的另一个HT)肯定要比迁移到不同numa的cpu上更快,因为一个core上的两个HT从L1 cache开始就是共享的。所以为了应对这些拓扑结构,出现了sched_domain。
相关结构体
struct sched_domain {
##父domain,如果当前是顶级domain的话,父domain是空
struct sched_domain __rcu *parent; /* top domain must be null terminated */
#子domain,如果当前是最低层domain的话,子domain是空,有多个子domain怎么挂?
struct sched_domain __rcu *child; /* bottom domain must be null terminated */
#sched_group,sched_domain主要是再调度层级上进行划分,sched_group表示在这个层级内cpu该怎么均衡?
#同一sched_domain中的sched_group形成的是一个环形链表
struct sched_group *groups; /* the balancing groups of the domain */
#负载均衡的最小和最大时间间隔
unsigned long min_interval; /* Minimum balance interval ms */
unsigned long max_interval; /* Maximum balance interval ms */
#如果busy的话减少balance
unsigned int busy_factor; /* less balancing by factor if busy */
#超过水线才balance?
unsigned int imbalance_pct; /* No balance until over watermark */
unsigned int cache_nice_tries; /* Leave cache hot tasks for # tries */
#允许numa不均衡的任务数量,应该是为了防止numa间频繁迁移任务,所以允许numa间有一点不均衡
unsigned int imb_numa_nr; /* Nr running tasks that allows a NUMA imbalance */
int nohz_idle; /* NOHZ IDLE status */
#见下面的SD_FLAG相关定义
int flags; /* See SD_* */
#domain的level,最底层的level是0,向上依次加1
int level;
/* Runtime fields. */
unsigned long last_balance; /* init to jiffies. units in jiffies */
unsigned int balance_interval; /* initialise to 1. units in ms. */
unsigned int nr_balance_failed; /* initialise to 0 */
/* idle_balance() stats */
u64 max_newidle_lb_cost;
unsigned long last_decay_max_lb_cost;
u64 avg_scan_cost; /* select_idle_sibling */
......
union {
void *private; /* used during construction */
struct rcu_head rcu; /* used during destruction */
};
struct sched_domain_shared *shared;
#本sched_domain中cpu的数量
unsigned int span_weight;
#cpumask?为什么不直接使用spumask指针?
unsigned long span[];
};
struct sched_group {
#下一个sched_group,这些了必须是一个环
struct sched_group *next; /* Must be a circular list */
atomic_t ref;
unsigned int group_weight;
struct sched_group_capacity *sgc;
int asym_prefer_cpu; /* CPU of highest priority in group */
int flags;
unsigned long cpumask[];
};
#切到idle的时候balance
SD_FLAG(SD_BALANCE_NEWIDLE, SDF_SHARED_CHILD | SDF_NEEDS_GROUPS)
#exec的时候balance
SD_FLAG(SD_BALANCE_EXEC, SDF_SHARED_CHILD | SDF_NEEDS_GROUPS)
#fork、clone的时候balance
SD_FLAG(SD_BALANCE_FORK, SDF_SHARED_CHILD | SDF_NEEDS_GROUPS)
#wakeup的时候balance
SD_FLAG(SD_BALANCE_WAKE, SDF_SHARED_CHILD | SDF_NEEDS_GROUPS)
#wake affine的时候balance,waker唤醒wake
SD_FLAG(SD_WAKE_AFFINE, SDF_SHARED_CHILD)
#cpu算力有差异
SD_FLAG(SD_ASYM_CPUCAPACITY, SDF_SHARED_PARENT | SDF_NEEDS_GROUPS)
SD_FLAG(SD_ASYM_CPUCAPACITY_FULL, SDF_SHARED_PARENT | SDF_NEEDS_GROUPS)
#共享算力,smt会设置?
SD_FLAG(SD_SHARE_CPUCAPACITY, SDF_SHARED_CHILD | SDF_NEEDS_GROUPS)
#共享package资源,比如cache
SD_FLAG(SD_SHARE_PKG_RESOURCES, SDF_SHARED_CHILD | SDF_NEEDS_GROUPS)
#只有一个balance实例?什么意思
SD_FLAG(SD_SERIALIZE, SDF_SHARED_PARENT | SDF_NEEDS_GROUPS)
SD_FLAG(SD_ASYM_PACKING, SDF_NEEDS_GROUPS)
#倾向于调度到同等级的兄弟sched_domain
SD_FLAG(SD_PREFER_SIBLING, SDF_NEEDS_GROUPS)
SD_FLAG(SD_OVERLAP, SDF_SHARED_PARENT | SDF_NEEDS_GROUPS)
#跨numa调度
SD_FLAG(SD_NUMA, SDF_SHARED_PARENT | SDF_NEEDS_GROUPS)
#意思是如果一个domain有这个flag的话,他的所有children都有相同的flag set
#define SDF_SHARED_CHILD 0x1
#同上
#define SDF_SHARED_PARENT 0x2
#只有sched_domain中有超过一个sched_group才有效?
#define SDF_NEEDS_GROUPS 0x4
#先通过这个宏生成一个enum
#然后通过下面的宏生成flag bit
/* Generate SD flag indexes */
#define SD_FLAG(name, mflags) __##name,
enum {
#include <linux/sched/sd_flags.h>
__SD_FLAG_CNT,
};
#undef SD_FLAG
/* Generate SD flag bits */
#define SD_FLAG(name, mflags) name = 1 << __##name,
enum {
#include <linux/sched/sd_flags.h>
};
#undef SD_FLAG
#这个是生成flag,把SD_FLAG展开 !!是使用两个非相当于把(mflags) & SDF_NEEDS_GROUPS)转换成0/1
#这一整个宏展开之后就是 (SD_BALANCE_NEWIDLE*1) | (SD_BALANCE_EXEC*1) |...| 0;
#define SD_FLAG(name, mflags) (name * !!((mflags) & SDF_NEEDS_GROUPS)) |
static const unsigned int SD_DEGENERATE_GROUPS_MASK =
#include <linux/sched/sd_flags.h>
0;
#undef SD_FLAG
初始化
start_kernel
->sched_init
->init_defrootdomain
->init_rootdomain #初始化一个root_domain,这时候的cpumask是全部的cpu
->rq_attach_root(rq, &def_root_domain) #遍历每个cpu初始化rq 各种调度器 smp内容之后,每个rq关联到def_root_domain
->arch_call_rest_init #rest init
->rest_init
->user_mode_thread(kernel_init, NULL, CLONE_FS) #这里创建了第一个用户进程
->kernel_init_freeable
->sched_init_smp #在smp_init之后
->sched_init_domains
->build_sched_domains
#看一下build_sched_domains的主要流程
#这里的cpu_map追了一下来源,应该是去掉了housekeeping的cpumask
build_sched_domains(const struct cpumask *cpu_map, struct sched_domain_attr *attr)
{
enum s_alloc alloc_state = sa_none;
struct sched_domain *sd;
struct s_data d;
struct rq *rq = NULL;
int i, ret = -ENOMEM;
bool has_asym = false;
#如果是空的,没必要继续了
if (WARN_ON(cpumask_empty(cpu_map)))
goto error;
alloc_state = __visit_domain_allocation_hell(&d, cpu_map);
if (alloc_state != sa_rootdomain)
goto error;
/* Set up domains for CPUs specified by the cpu_map: */
#真正的用给出的cpu_map去创建sched_domain
#遍历所有cpu_map中的所有cpu
for_each_cpu(i, cpu_map) {
struct sched_domain_topology_level *tl;
sd = NULL;
#遍历所有的sd_topology
for_each_sd_topology(tl) {
if (WARN_ON(!topology_span_sane(tl, cpu_map, i)))
goto error;
#创建sched_domain
#这个函数先调用sd_init初始化sched_domain
#然后如果有child,就继续处理level parent等相关内容
#所以实际上sd_init才是真正去创建这个sched_domain的
#sd_init是去完整的初始化sched_domain结构体
sd = build_sched_domain(tl, cpu_map, attr, sd, i);
has_asym |= sd->flags & SD_ASYM_CPUCAPACITY;
if (tl == sched_domain_topology)
*per_cpu_ptr(d.sd, i) = sd;
if (tl->flags & SDTL_OVERLAP)
sd->flags |= SD_OVERLAP;
if (cpumask_equal(cpu_map, sched_domain_span(sd)))
break;
}
}
#创建sched_groups
#遍历cpu_map中的每个cpu
for_each_cpu(i, cpu_map) {
#从最底层sched_domain向上遍历,也就是从最底层向上构建
for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent) {
sd->span_weight = cpumask_weight(sched_domain_span(sd));
if (sd->flags & SD_OVERLAP) {
if (build_overlap_sched_groups(sd, i))
goto error;
} else {
#真正的去构建sched_group
#这里遍历sched_domain span中的所有cpu
#然后获取该cpu所属的group,看上去就是一些cpumask运算,如果没有child,则组内就当前一个cpu,如果有child,就把child的cpumask也算上
#最后给next这些赋值,构成环链
#注意这里没有span的话,也就是sd_init中的sched_domain没有计算出交集的话,就不会去构建sched_group
if (build_sched_groups(sd, i))
goto error;
}
}
}
/*
* Calculate an allowed NUMA imbalance such that LLCs do not get
* imbalanced.
*/
......
/* Calculate CPU capacity for physical packages and nodes */
......
/* Attach the domains */
#把domain加到rq上
rcu_read_lock();
#遍历每个cpu
for_each_cpu(i, cpu_map) {
rq = cpu_rq(i);
sd = *per_cpu_ptr(d.sd, i);
/* Use READ_ONCE()/WRITE_ONCE() to avoid load/store tearing: */
if (rq->cpu_capacity_orig > READ_ONCE(d.rd->max_cpu_capacity))
WRITE_ONCE(d.rd->max_cpu_capacity, rq->cpu_capacity_orig);
#真正的去attach domain
#这里会去从base sd向上一直遍历判断,如果有parent和child决策是一样的,就把parent移除,直接让child继承祖父
#做完这些,把sd挂在rq上
cpu_attach_domain(sd, d.rd, i);
}
rcu_read_unlock();
......
ret = 0;
error:
__free_domain_allocs(&d, alloc_state, cpu_map);
return ret;
}
所以这里可以大概总结下:简单来说,就是构建sched_domain->构建sched_group->把sched_domain加到rq上。关于构建sched_domain和sched_group的具体细节可以看对应的build_sched_domain和build_sched_groups函数。
注:
1.构建sched_group,为什么自下到上?很妙,一层一层向上构建的时候能够直接根据child sched_domain的span和当前cpu来计算group有哪些cpu,借注释中的一个图可以看的比较明显,如下,smt的两个group可能就是cpu0 cpu1,然后再向上构建的时候,也就是构建mc的时候,因为mc有child,所以就去找他的child的span(注意不是找child的sched_group,而是找child的sched_domain),有两个child,把两个child的sched_domain的span直接拿过来 就是[0 1] [2 3]两个group了
* Take for instance a 2 threaded, 2 core, 2 cache cluster part:
*
* CPU 0 1 2 3 4 5 6 7
*
* DIE [ ]
* MC [ ] [ ]
* SMT [ ] [ ] [ ] [ ]
*
* - or -
*
* DIE 0-7 0-7 0-7 0-7 0-7 0-7 0-7 0-7
* MC 0-3 0-3 0-3 0-3 4-7 4-7 4-7 4-7
* SMT 0-1 0-1 2-3 2-3 4-5 4-5 6-7 6-7
*
* CPU 0 1 2 3 4 5 6 7
#for_each_sd_topology这个遍历的所有拓扑是在哪建立的呢?
kernel_init_freeable
->smp_init
->smp_cpus_done
->native_smp_cpus_done
->build_sched_topology
#看一下build_sched_topology这个函数
#可以看到,只要开启了相关的配置选项,就会往x86_topology中添加并初始化相关的sched_domain结构体
static struct sched_domain_topology_level x86_topology[6];
static void __init build_sched_topology(void)
{
int i = 0;
#ifdef CONFIG_SCHED_SMT
x86_topology[i++] = (struct sched_domain_topology_level){
cpu_smt_mask, x86_smt_flags, SD_INIT_NAME(SMT)
};
#endif
#ifdef CONFIG_SCHED_CLUSTER
/*
* For now, skip the cluster domain on Hybrid.
*/
if (!cpu_feature_enabled(X86_FEATURE_HYBRID_CPU)) {
x86_topology[i++] = (struct sched_domain_topology_level){
cpu_clustergroup_mask, x86_cluster_flags, SD_INIT_NAME(CLS)
};
}
#endif
#ifdef CONFIG_SCHED_MC
x86_topology[i++] = (struct sched_domain_topology_level){
cpu_coregroup_mask, x86_core_flags, SD_INIT_NAME(MC)
};
#endif
/*
* When there is NUMA topology inside the package skip the DIE domain
* since the NUMA domains will auto-magically create the right spanning
* domains based on the SLIT.
*/
if (!x86_has_numa_in_package) {
x86_topology[i++] = (struct sched_domain_topology_level){
cpu_cpu_mask, SD_INIT_NAME(DIE)
};
}
/*
* There must be one trailing NULL entry left.
*/
BUG_ON(i >= ARRAY_SIZE(x86_topology)-1);
set_sched_topology(x86_topology);
}
注:
1.for_each_sd_topology这个遍历是遍历的sched_domain_topology指针指向的sched_domain_topology_level,它本来有一个默认的default_topology,但是我们x86架构执行了上面的build_sched_topology函数后,在最后会执行set_sched_topology,把sched_domain_topology指针指向的内容换成x86_topology,这样遍历的时候就是去遍历x86_topology结构体了
2.有没有注意到,怎么没看见numa的sched_domain呢?其实它在sched_init_smp->sched_init_numa函数中,在这里会创建numa sched_domain的相关信息添加到set_sched_topology中。
3.build_sched_topology中可以看到,只要配置选项中打开了相应的配置,那就会创建对应的sched_domain,那如果实际上不支持该内容怎么办呢?比如实际上没有开启smt,那是怎么跳过smt sched_domain的构建的呢?哭了,这个找了很久。在sd_init那个函数那里,也就是去真正初始化sched_domain的时候,有以下几句,sd_span = sched_domain_span(sd);cpumask_and(sd_span, cpu_map, tl->mask(cpu));sd_id = cpumask_first(sd_span);,意思就是获取当前sched_domain的cpumask(这个其实就是去调用当前sched_domain的mask函数,这个其实在build_sched_topology中可以找到,就是那些cpu_smt_mask、cpu_clustergroup_mask,这些大概就是以当前cpu做参数去调用架构相关的函数,获取同smt llc之类的cpu的mask),然后和当前的cpu_map取交集。很明显,如果没开启smt的话,取回的cpumask_and肯定是空,这样的话sd_id就肯定是空。然后后面构建sched_group的时候也不在构建,然后在后面的cpu_attach_domain中会判断parent是不是没用,如果没用的话就把他删掉。其实有个小疑问,为什么这么麻烦,构建了没用的sched_domain然后往rq挂的时候再去判断,再把没用的给dettach然后destroy掉,为什么不直接在构建sched_domain sched_group的时候不去构建??
以上,是相关sched_domain、sched_group等内容的初始化过程:在系统启动时就会根据配置选项来创建一些sched_domain_topology_level结构体,这里就可能包含smt mc die numa(不过numa不是和前面的同时创建的)这些内容。然后就遍历每个cpu(housekeeping除外)去初始化sched_domain,然后再去初始化sched_group,最后把sched_domain挂到每个cpu对应的rq上(在这之前,还会把没用的sched_domain destroy掉,精简结构)
调度
有三种情况需要为task选择rq,也就是选择cpu,分别是fork exec和wakeup的时候,最终都会去调用select_task_rq,对于cfs来说,就是select_task_rq_fair
select_task_rq_fair(struct task_struct *p, int prev_cpu, int wake_flags)
{
int sync = (wake_flags & WF_SYNC) && !(current->flags & PF_EXITING);
struct sched_domain *tmp, *sd = NULL;
int cpu = smp_processor_id();
int new_cpu = prev_cpu;
int want_affine = 0;
/* SD_flags and WF_flags share the first nibble */
int sd_flag = wake_flags & 0xF;
lockdep_assert_held(&p->pi_lock);
#如果传入的flag有WF_TTWU bit
if (wake_flags & WF_TTWU) {
#记录下当前被唤醒的task
record_wakee(p);
#能效调度相关
if (sched_energy_enabled()) {
new_cpu = find_energy_efficient_cpu(p, prev_cpu);
if (new_cpu >= 0)
return new_cpu;
new_cpu = prev_cpu;
}
#确定是不是wake_wide,也就是频繁互相唤醒
##以及确定目标cpu是否在可以运行task的cpumask中
want_affine = !wake_wide(p) && cpumask_test_cpu(cpu, p->cpus_ptr);
}
rcu_read_lock();
#遍历sched_domain,从当前cpu所处的sd开始,向parent遍历
for_each_domain(cpu, tmp) {
#如果want_affine且sched_domain的flag中有SD_WAKE_AFFINE且sched_domain中的span中包含prev_cpu
if (want_affine && (tmp->flags & SD_WAKE_AFFINE) &&
cpumask_test_cpu(prev_cpu, sched_domain_span(tmp))) {
if (cpu != prev_cpu)
#cpu不等于prev_cpu时,wake_affine
new_cpu = wake_affine(tmp, p, cpu, prev_cpu, sync);
sd = NULL; /* Prefer wake_affine over balance flags */
break;
}
/*
* Usually only true for WF_EXEC and WF_FORK, as sched_domains
* usually do not have SD_BALANCE_WAKE set. That means wakeup
* will usually go to the fast path.
*/
#这里写了一般只有WF_EXEC and WF_FORK的情况下是true,wakeup一般是false,所以总是走快速路径
if (tmp->flags & sd_flag)
sd = tmp;
else if (!want_affine)
break;
}
#如果sd不空,走慢路径
if (unlikely(sd)) {
/* Slow path */
new_cpu = find_idlest_cpu(sd, p, cpu, prev_cpu, sd_flag);
} else if (wake_flags & WF_TTWU) { /* XXX always ? */
#否则,有WF_TTWU的话,走快路径
/* Fast path */
new_cpu = select_idle_sibling(p, prev_cpu, new_cpu);
}
rcu_read_unlock();
return new_cpu;
}
#以下常用的几个WF_FLAG
#define WF_EXEC 0x02 /* Wakeup after exec; maps to SD_BALANCE_EXEC */
#define WF_FORK 0x04 /* Wakeup after fork; maps to SD_BALANCE_FORK */
#define WF_TTWU 0x08 /* Wakeup; maps to SD_BALANCE_WAKE */
这块总结一下:
- 需要唤醒进程的时候,走到select_task_rq_fair函数,去选择要在哪个rq上唤醒进程。其中wake_flags传入的一般是WF_EXEC、WF_FORK、WF_TTWU三种,分别表示exec后唤醒,映射到SD_BALANCE_EXEC;fork后唤醒,映射到SD_BALANCE_FORK;普通wakeup,映射到SD_BALANCE_WAKE
- 如过传入的wake_flags中有WF_TTWU,确定是不是想要affine
- 从当前cpu(注意这里时waker所在的cpu)的sched_domain向上遍历,如果want_affine且遍历的sched_domain中有SD_WAKE_AFFINE且遍历的sched_domain的span中有prev_cpu(也就是被唤醒的wakee进程上一次运行时的cpu),然后waker所在的cpu和wakee上一次运行的cpu不是同一个cpu,那么使用wake_affine函数选择一个cpu来作为target(后面进入快速路径去选择)。如果不满足上面的条件,继续向上遍历,如果sched_domain的flags中没有sd_flag相关的bit的话(一般只有WF_EXEC and WF_FORK的情况下是true,wakeup一般是false),就不继续遍历了,因为没什么必要了。
- 如果sd不空,走find_idlest_cpu去选一个运行wakee的cpu;否则走select_idle_sibling快速路径去选一个运行wakee的cpu。(能走到这里,除了第一个break前把sd设置为null,可能会走快路径了;第二个break或者正常遍历完sched_domain走过来,sd不为空)
#wake_affine实现
static int wake_affine(struct sched_domain *sd, struct task_struct *p,
int this_cpu, int prev_cpu, int sync)
{
int target = nr_cpumask_bits;
if (sched_feat(WA_IDLE))
#如果有idle的cpu,从prev和this选一个idle的cpu出来,都idle的话优先选prev
target = wake_affine_idle(this_cpu, prev_cpu, sync);
if (sched_feat(WA_WEIGHT) && target == nr_cpumask_bits)
#计算this和prev的weight来选择负载清的cpu
target = wake_affine_weight(sd, p, this_cpu, prev_cpu, sync);
schedstat_inc(p->stats.nr_wakeups_affine_attempts);
if (target != this_cpu)
return prev_cpu;
schedstat_inc(sd->ttwu_move_affine);
schedstat_inc(p->stats.nr_wakeups_affine);
return target;
}
#慢路径
static inline int find_idlest_cpu(struct sched_domain *sd, struct task_struct *p,
int cpu, int prev_cpu, int sd_flag)
{
#先设置为waker的cpu
int new_cpu = cpu;
#如果wakee的cpumask与sched_domain的
if (!cpumask_intersects(sched_domain_span(sd), p->cpus_ptr))
return prev_cpu;
/*
* We need task's util for cpu_util_without, sync it up to
* prev_cpu's last_update_time.
*/
#同步负载?
if (!(sd_flag & SD_BALANCE_FORK))
sync_entity_load_avg(&p->se);
#遍历sd,从高到低
while (sd) {
struct sched_group *group;
struct sched_domain *tmp;
int weight;
#flags不支持的话,到child
if (!(sd->flags & sd_flag)) {
sd = sd->child;
continue;
}
#找最空闲的sched_group,从当前的sched_domain
#有一个group_type的enum可以描述当前sched_group的空闲状态
group = find_idlest_group(sd, p, cpu);
if (!group) {
sd = sd->child;
continue;
}
#找最空闲的cpu,从当前sched_group
#遍历该sched_group中的cpu
new_cpu = find_idlest_group_cpu(group, p, cpu);
#如果这个找到的cpu就是waker的cpu,继续向下走
if (new_cpu == cpu) {
/* Now try balancing at a lower domain level of 'cpu': */
sd = sd->child;
continue;
}
/* Now try balancing at a lower domain level of 'new_cpu': */
cpu = new_cpu;
weight = sd->span_weight;
sd = NULL;
#需要在更低等级的sched_domain去搜
#比如当前找到的是numa层的new_cpu,需要继续向下,再去mc smt这些去找
for_each_domain(cpu, tmp) {
if (weight <= tmp->span_weight)
break;
if (tmp->flags & sd_flag)
sd = tmp;
}
}
return new_cpu;
}
#快路径
static int select_idle_sibling(struct task_struct *p, int prev, int target)
{
bool has_idle_core = false;
struct sched_domain *sd;
unsigned long task_util, util_min, util_max;
int i, recent_used_cpu;
/*
* On asymmetric system, update task utilization because we will check
* that the task fits with cpu's capacity.
*/
if (sched_asym_cpucap_active()) {
sync_entity_load_avg(&p->se);
task_util = task_util_est(p);
util_min = uclamp_eff_value(p, UCLAMP_MIN);
util_max = uclamp_eff_value(p, UCLAMP_MAX);
}
/*
* per-cpu select_rq_mask usage
*/
lockdep_assert_irqs_disabled();
#如果target idle,就直接选taget
if ((available_idle_cpu(target) || sched_idle_cpu(target)) &&
asym_fits_cpu(task_util, util_min, util_max, target))
return target;
/*
* If the previous CPU is cache affine and idle, don't be stupid:
*/
#如果prev与target共享缓存,且prev idle,返回prev
if (prev != target && cpus_share_cache(prev, target) &&
(available_idle_cpu(prev) || sched_idle_cpu(prev)) &&
asym_fits_cpu(task_util, util_min, util_max, prev))
return prev;
#如果waker是per cpu的内核线程,且正在运行的就是这个内核线程,且prev就是当前cpu且当前cpu几乎空闲,直接返回prev
if (is_per_cpu_kthread(current) &&
in_task() &&
prev == smp_processor_id() &&
this_rq()->nr_running <= 1 &&
asym_fits_cpu(task_util, util_min, util_max, prev)) {
return prev;
}
/* Check a recently used CPU as a potential idle candidate: */
#如果task的recent_used_cpu不与prev target相同且它与target共享cache且该cpu几乎空闲,直接返回
recent_used_cpu = p->recent_used_cpu;
p->recent_used_cpu = prev;
if (recent_used_cpu != prev &&
recent_used_cpu != target &&
cpus_share_cache(recent_used_cpu, target) &&
(available_idle_cpu(recent_used_cpu) || sched_idle_cpu(recent_used_cpu)) &&
cpumask_test_cpu(recent_used_cpu, p->cpus_ptr) &&
asym_fits_cpu(task_util, util_min, util_max, recent_used_cpu)) {
return recent_used_cpu;
}
/*
* For asymmetric CPU capacity systems, our domain of interest is
* sd_asym_cpucapacity rather than sd_llc.
*/
#异构相关,先忽略
if (sched_asym_cpucap_active()) {
sd = rcu_dereference(per_cpu(sd_asym_cpucapacity, target));
/*
* On an asymmetric CPU capacity system where an exclusive
* cpuset defines a symmetric island (i.e. one unique
* capacity_orig value through the cpuset), the key will be set
* but the CPUs within that cpuset will not have a domain with
* SD_ASYM_CPUCAPACITY. These should follow the usual symmetric
* capacity path.
*/
if (sd) {
i = select_idle_capacity(p, sd, target);
return ((unsigned)i < nr_cpumask_bits) ? i : target;
}
}
#获取target共享llc的sched_domain
sd = rcu_dereference(per_cpu(sd_llc, target));
if (!sd)
return target;
#如果开着smt
#查找是否有idle的core,如果没有在smt中找空闲的
if (sched_smt_active()) {
has_idle_core = test_idle_cores(target);
if (!has_idle_core && cpus_share_cache(prev, target)) {
i = select_idle_smt(p, prev);
if ((unsigned int)i < nr_cpumask_bits)
return i;
}
}
#在共享llc的sched_domain中搜索
i = select_idle_cpu(p, sd, has_idle_core, target);
if ((unsigned)i < nr_cpumask_bits)
return i;
return target;
}
以上:
- wake_affine是从waker和wakee的cpu中选择一个出来,并不直接用,还得到快速路径中去确定
- find_idlest_cpu慢路径,从高到低遍历sched_domain,找到最空闲的sched_gtoup中最空闲的cpu
- select_idle_sibling:检查target能否直接返回;检查prev能否直接返回;特殊场景,如果是内核线程wakeup wakee的场景以及满足一些其他条件,直接返回prev;检查能够直接返回wakee最近使用的cpu recent_used_cpu;如果以上都不满足,在共享llc的sched_domain中搜索,查找target cpu共享llc的物理核中有没有idle的物理核,有则返回,没有继续查找有没有空闲的smt,有则直接返回(这里有先找idle的物理核,找不到再退而求其次找idle的逻辑核),如果还没有,就select_idle_cpu全局搜索。
注:
1.当前WA_IDLE和WA_WEIGHT应该都是开着的,WA_IDLE是指任务唤醒时优先选择idle cpu,WA_WEIGHT是指在唤醒时,根据cpu负载权重选择cpu
所以为什么会出现cpu利用率分层的现象?
首先,进程是普通的被唤醒的情况(非fork核exec),那么这时候传入的wake_flags就是WF_TTWU,那么它们被唤醒的时候选核逻辑就是走wake_affine和select_idle_sibling。wake_affine会根据idle等情况从waker所在的cpu和上次运行wakee的cpu中选择一个cpu作为target,然后走select_idle_sibling,在这里,如果target、prev、recent_used_cpu等前面这些逻辑都不满足,如上面所说,就会去找与target共享llc的sched_domain中去找空闲的物理核,找到空闲物理核后需要再选择一个cpu,在select_idle_cpu中,走到select_idle_core函数,select_idle_core会判断如果该core是空闲的(smt上的两个cpu都idle)就直接返回了。在当前的smt 顺序拓扑结构中,就总是优先遍历偶数核。
因此,看上去就是出现cpu利用率分层了。
社区大佬们认为这不算问题,是正常的
实验
- 如上所说,出现cpu利用率分层主要是因为wakeup的进程走快速路径去选核,所以可能出现这种情况。那如果我手动把sd_flag都调成支持SD_BALANCE_WAKE呢?
我搞了一个16c的机器,cpu拓扑如下,可以看到0 1是在一个core上的
# CPU,Core,Socket,Node,,L1d,L1i,L2,L3
0,0,0,0,,0,0,0,0
1,0,0,0,,0,0,0,0
2,1,0,0,,1,1,1,0
3,1,0,0,,1,1,1,0
4,2,0,0,,2,2,2,0
5,2,0,0,,2,2,2,0
6,3,0,0,,3,3,3,0
7,3,0,0,,3,3,3,0
8,4,0,0,,4,4,4,0
9,4,0,0,,4,4,4,0
10,5,0,0,,5,5,5,0
11,5,0,0,,5,5,5,0
12,6,0,0,,6,6,6,0
13,6,0,0,,6,6,6,0
14,7,0,0,,7,7,7,0
15,7,0,0,,7,7,7,0
我起了三个stress-ng -c 8 –cpu-load=40,可以看到,同一个core上的偶数cpu利用率比奇数要高一些,或者直接起一个stress-ng -c 24 –cpu-load=40就可以复现
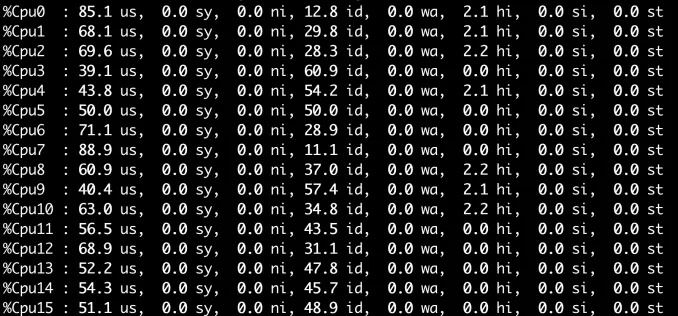
当前我的/proc/sys/kernel/sched_domain/X/domain0/flags是4783,domain1/flags是4655,现在分别把他们都加上
cd /proc/sys/kernel/sched_domain/
for i in ls;do echo 4799 > $i/domain0/flags && echo 4671 > $i/domain1/flags;done
echo 1 > /proc/sys/kernel/sched_autogroup_enabled
发现没有用,为什么?
通过ftrace可以看到都是try_to_wake_up唤醒,也就是传入的都是WF_TTWU没问题
5) <idle>-0 => stress--2461
------------------------------------------
5) | select_task_rq_fair() {
5) 0.080 us | available_idle_cpu();
5) 0.060 us | available_idle_cpu();
5) 0.091 us | available_idle_cpu();
5) 0.122 us | available_idle_cpu();
5) 0.102 us | available_idle_cpu();
5) 0.097 us | available_idle_cpu();
5) 0.096 us | available_idle_cpu();
5) 0.100 us | available_idle_cpu();
5) 0.159 us | available_idle_cpu();
5) 0.161 us | available_idle_cpu();
5) 7.256 us | }
7) | select_task_rq_fair() {
7) 0.062 us | available_idle_cpu();
7) 0.535 us | }
7) | select_task_rq_fair() {
7) 0.061 us | available_idle_cpu();
7) 0.495 us | }
4) | select_task_rq_fair() {
4) 0.081 us | available_idle_cpu();
4) 0.216 us | available_idle_cpu();
4) 0.057 us | available_idle_cpu();
4) 1.752 us | }
如上,可以看到执行了很多available_idle_cpu,但是仅凭这个还不足以知道到底走没走慢路径,因为快慢路径都会执行这个,唉这里面好多static 好多inline的函数,不好找
噢 不用,其实看一下select_task_rq_fair函数的执行过程可以发现,如果want_affine为假,那么第一次进入遍历sched_domain的循环就会跳出,去走快速路径;如果want_affine为真,在当前单numa且所有任务不设置绑核的情况下,应该是肯定能走到第一个break哪里的,那里把sd设置为null了,所以跳出之后,也是会去走快速路径,所以,把SD_BALANCE_WAKE加到sched_domain的flags中应该是没用的。
那为什么没有idle core的情况下还是会出现cpu利用率分层的情况?
watch -n 2 ‘grep “nr_running” /proc/sched_debug’看一下
Every 2.0s: grep "nr_running" /proc/sched_debug bd-gz-live-comet-01: Mon Apr 7 14:05:43 2025
.nr_running : 0
.nr_running : 0
.nr_running : 0
.nr_running : 0
.nr_running : 0
.rt_nr_running : 0
.dl_nr_running : 0
.nr_running : 0
.nr_running : 0
.nr_running : 0
.nr_running : 0
.nr_running : 0
.rt_nr_running : 0
.dl_nr_running : 0
.nr_running : 0
.nr_running : 0
.nr_running : 0
.nr_running : 0
.nr_running : 0
.rt_nr_running : 0
.dl_nr_running : 0
.nr_running : 1
.nr_running : 0
.nr_running : 1
.nr_running : 0
.nr_running : 1
.rt_nr_running : 0
.dl_nr_running : 0
.nr_running : 1
.nr_running : 0
其实可以看到,在负载不是那么高的情况下,可能在走快路径选择cpu的时候,判断到有些core就是idle的,然后可以复用上面的逻辑,从for_each_cpu(cpu, cpu_smt_mask(core))去遍历的话,就是从偶数cpu去开始的,所以可能也会出现这个问题。
所以 我就算修改了sched_domain的flags,wakeup唤醒的进程其实还是会走快路径的
- 最开始看到,set sched_domain的时候是把housekeeping的cpu去掉了,那么这种cpu上还有没有sd呢?比较好奇
crash> runq -c 0,1
CPU 0 RUNQUEUE: ffff889fff2331c0
CURRENT: PID: 0 TASK: ffffffffb560a340 COMMAND: "swapper/0"
RT PRIO_ARRAY: ffff889fff233440
[no tasks queued]
CFS RB_ROOT: ffff889fff233280
[no tasks queued]
CPU 1 RUNQUEUE: ffff889fff2731c0
CURRENT: PID: 0 TASK: ffff8881030f8000 COMMAND: "swapper/1"
RT PRIO_ARRAY: ffff889fff273440
[no tasks queued]
CFS RB_ROOT: ffff889fff273280
[no tasks queued]
crash> rq ffff889fff2331c0 |grep sd
nohz_csd = {
func = 0xffffffffb36f29a0 <nohz_csd_func>,
throttled_csd_list = {
sd = 0xffff888106469000,
hrtick_csd = {
cfsb_csd = {
func = 0xffffffffb3711ad0 <__cfsb_csd_unthrottle>,
cfsb_csd_list = {
crash> rq ffff889fff2731c0 |grep sd
nohz_csd = {
func = 0xffffffffb36f29a0 <nohz_csd_func>,
throttled_csd_list = {
sd = 0x0,
hrtick_csd = {
cfsb_csd = {
func = 0xffffffffb3711ad0 <__cfsb_csd_unthrottle>,
cfsb_csd_list = {
crash>
如上,我搞了个机器,其中cpu 0是非isolated的,cpu 1是isolated,可以看到cpu1的rq中果然没有sd
符合上面的housekeeping的cpu不构建sd的逻辑。,因为housekeeping的cpu就不参与cfs调度了
为什么虚机cpu拓扑换了就没问题了?
后记
- 关于balance是怎么做的,后面还得再看
- 看这块的时候看待fair class要比rt dl这些提前很多初始化,为什么?
这块ds老师给的理由是:cfs是默认的普通进程调度类,负责大多数非实时任务的公平调度。它需要在内核启动早期就可用;实时调度类的优先级高于 CFS,但其任务通常在内核启动后期(如设备驱动初始化阶段)才创建,因此延迟初始化不影响系统启动流程
为什么是smt是[0 1] [2 3] [4 5] [6 7]这种拓扑才会出问题,[0 4] [1 5] [2 6] [3 7]这种不会出问题?
这个要追到快路径中,如果前面target prev recent_used_cpu不满足,就去与target共享llc的sched_domain中去,在select_idle_cpu中,有这样一段
static int select_idle_cpu(struct task_struct *p, struct sched_domain *sd, bool has_idle_core, int target) { ...... for_each_cpu_wrap(cpu, cpus, target + 1) { if (has_idle_core) { i = select_idle_core(p, cpu, cpus, &idle_cpu); if ((unsigned int)i < nr_cpumask_bits) return i; } else { if (!--nr) return -1; idle_cpu = __select_idle_cpu(cpu, p); if ((unsigned int)idle_cpu < nr_cpumask_bits) break; } } static int select_idle_core(struct task_struct *p, int core, struct cpumask *cpus, int *idle_cpu) { bool idle = true; int cpu; for_each_cpu(cpu, cpu_smt_mask(core)) { if (!available_idle_cpu(cpu)) { idle = false; if (*idle_cpu == -1) { if (sched_idle_cpu(cpu) && cpumask_test_cpu(cpu, p->cpus_ptr)) { *idle_cpu = cpu; break; } continue; } break; } if (*idle_cpu == -1 && cpumask_test_cpu(cpu, p->cpus_ptr)) *idle_cpu = cpu; } if (idle) return core; cpumask_andnot(cpus, cpus, cpu_smt_mask(core)); return -1; }其实这个就非常明显了,快路径中走到select_idle_cpu去选择idle的cpu的话,首先它是这样循环的for_each_cpu_wrap(cpu, cpus, target + 1),也就是从target+1的位置开始,去调用select_idle_core,select_idle_core会判断如果该core是空闲的(smt上的两个cpu都idle)就直接返回了。
这在[0 4] [1 5] [2 6] [3 7]这种对称的拓扑上没有问题,cpu从target+1开始遍历的时候,如果target+1在前一半cpu(0-3)那么就优先检查core内比较小的cpu号,如果target+1在后一半cpu(4-7),那么优先检查的就是core内比较大的cpu号。因此,这个遍历只和target的位置有关,只要target是随机的,那么选择的cpu应该也是随机的。
但是在[0 1] [2 3] [4 5] [6 7]这种顺序拓扑中,检查core是否idle的时候总是会先遍历到偶数核。因此,在target+1是奇数核且target+1 cpu不是idle core的情况下,几乎总是去选择偶数核。
参考
https://cloud.tencent.com/developer/article/2411277
https://cloud.tencent.com/developer/article/193993
https://www.cnblogs.com/banshanjushi/p/18599570
https://lore.kernel.org/lkml/1689842053-5291-1-git-send-email-Kenan.Liu@linux.alibaba.com/
后后记
又是一整天,清明假期的最后一天就这么过去了,噗
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 857879363@qq.com