NBD(Network Block Device),允许把远端的块设备映射到本地,像访问本地块设备一样访问远端设备
学习
首先只有配置了CONFIG_BLK_DEV_NBD配置选项才能启用nbd驱动的编译
模块参数
insmod/modprobe nbd模块的时候,可以带两个参数:
nbds_max:初始化的nbd设备数,默认16个,加载nbd模块后可以看到/dev下又nbd0-nbd15
max_part:指定每个nbd设备的最大分区数,默认16个
相关结构体
struct nbd_device {
#用于多队列的id请求的tag set
struct blk_mq_tag_set tag_set;
#index,就是/dev/nbd0 /dev/nbd1中的0 1
int index;
#config和设备的引用计数
refcount_t config_refs;
refcount_t refs;
struct nbd_config *config;
struct mutex config_lock;
struct gendisk *disk;
struct workqueue_struct *recv_workq;
struct work_struct remove_work;
struct list_head list;
struct task_struct *task_setup;
unsigned long flags;
#nbd-client的pid
pid_t pid; /* pid of nbd-client, if attached */
#后端设备的标识符
char *backend;
};
初始化
#define NBD_MAJOR 43 /* Network block device */
static int __init nbd_init(void)
{
#检查参数合法性
......
#注册一个blk设备,名字叫nbd,主设备号是43
if (register_blkdev(NBD_MAJOR, "nbd"))
return -EIO;
#分配一个workqueue,看名字的意思是delete nbd的?
nbd_del_wq = alloc_workqueue("nbd-del", WQ_UNBOUND, 0);
if (!nbd_del_wq) {
unregister_blkdev(NBD_MAJOR, "nbd");
return -ENOMEM;
}
#初始化一个netlink family,关于netlink的原理及使用后面再写一篇
if (genl_register_family(&nbd_genl_family)) {
destroy_workqueue(nbd_del_wq);
unregister_blkdev(NBD_MAJOR, "nbd");
return -EINVAL;
}
#这里如果配置了CONFIG_DEBUG_FS,会在/sys/kernel/debug下创建一个nbd目录,可以用来debug
nbd_dbg_init();
#添加nbds_max个设备
for (i = 0; i < nbds_max; i++)
nbd_dev_add(i, 1);
return 0;
}
#register_blkdev过程,注册一个新的blk device
int __register_blkdev(unsigned int major, const char *name,
void (*probe)(dev_t devt))
{
#处理major为0的情况。也就是没有指定主设备号,临时随机生成一个主设备号
if (major == 0) {
#从高到低遍历major_names数组,尝试找到一个没有被分配过的设备号
for (index = ARRAY_SIZE(major_names)-1; index > 0; index--) {
if (major_names[index] == NULL)
break;
}
if (index == 0) {
printk("%s: failed to get major for %s\n",
__func__, name);
ret = -EBUSY;
goto out;
}
#找到就赋值给major
major = index;
ret = major;
}
#不能超过最大值,当前是512,6.5内核上
if (major >= BLKDEV_MAJOR_MAX) {
pr_err("%s: major requested (%u) is greater than the maximum (%u) for %s\n",
__func__, major, BLKDEV_MAJOR_MAX-1, name);
ret = -EINVAL;
goto out;
}
#从slab分配一个blk_major_name结构体
p = kmalloc(sizeof(struct blk_major_name), GFP_KERNEL);
if (p == NULL) {
ret = -ENOMEM;
goto out;
}
#给这个结构体的相关元素赋值
p->major = major;
#ifdef CONFIG_BLOCK_LEGACY_AUTOLOAD
p->probe = probe;
#endif
strscpy(p->name, name, sizeof(p->name));
p->next = NULL;
index = major_to_index(major);
spin_lock(&major_names_spinlock);
#遍历该index下的所有blk_major_name节点
for (n = &major_names[index]; *n; n = &(*n)->next) {
if ((*n)->major == major)
break;
}
#如果!n,也就是n是null,说明这个major还没被注册,可以挂上这个链表
if (!*n)
*n = p;
else
ret = -EBUSY;
spin_unlock(&major_names_spinlock);
if (ret < 0) {
printk("register_blkdev: cannot get major %u for %s\n",
major, name);
kfree(p);
}
out:
mutex_unlock(&major_names_lock);
return ret;
}
#nbd_dev_add过程
static struct nbd_device *nbd_dev_add(int index, unsigned int refs)
{
struct nbd_device *nbd;
struct gendisk *disk;
int err = -ENOMEM;
#从slab申请nbd_device结构体
nbd = kzalloc(sizeof(struct nbd_device), GFP_KERNEL);
if (!nbd)
goto out;
#配置tag_set
nbd->tag_set.ops = &nbd_mq_ops;
nbd->tag_set.nr_hw_queues = 1;
nbd->tag_set.queue_depth = 128;
nbd->tag_set.numa_node = NUMA_NO_NODE;
nbd->tag_set.cmd_size = sizeof(struct nbd_cmd);
nbd->tag_set.flags = BLK_MQ_F_SHOULD_MERGE |
BLK_MQ_F_BLOCKING;
nbd->tag_set.driver_data = nbd;
#init一个work,执行的函数是nbd_dev_remove_work,就是删掉tag_set gendisk等相关内容,最后释放nbd_device
INIT_WORK(&nbd->remove_work, nbd_dev_remove_work);
nbd->backend = NULL;
err = blk_mq_alloc_tag_set(&nbd->tag_set);
if (err)
goto out_free_nbd;
#这块从加锁到释放都是在从xarray中申请一个index
#看到idr又想起之前写修改进程信息的内核模块的时候,namespace管理pid会通过idr来申请pid
mutex_lock(&nbd_index_mutex);
if (index >= 0) {
err = idr_alloc(&nbd_index_idr, nbd, index, index + 1,
GFP_KERNEL);
if (err == -ENOSPC)
err = -EEXIST;
} else {
err = idr_alloc(&nbd_index_idr, nbd, 0,
(MINORMASK >> part_shift) + 1, GFP_KERNEL);
if (err >= 0)
index = err;
}
nbd->index = index;
mutex_unlock(&nbd_index_mutex);
if (err < 0)
goto out_free_tags;
#这里是分配gendisk
disk = blk_mq_alloc_disk(&nbd->tag_set, NULL);
if (IS_ERR(disk)) {
err = PTR_ERR(disk);
goto out_free_idr;
}
nbd->disk = disk;
#这里申请workqueue,用于接收server的数据包
nbd->recv_workq = alloc_workqueue("nbd%d-recv",
WQ_MEM_RECLAIM | WQ_HIGHPRI |
WQ_UNBOUND, 0, nbd->index);
if (!nbd->recv_workq) {
dev_err(disk_to_dev(nbd->disk), "Could not allocate knbd recv work queue.\n");
err = -ENOMEM;
goto out_err_disk;
}
/*
* Tell the block layer that we are not a rotational device
*/
#初始化gendisk
#这个注释的意思是通知block layer这不是旋转的设备,也就是这不是机械硬盘,不用去搞寻道优化那些
blk_queue_flag_set(QUEUE_FLAG_NONROT, disk->queue);
disk->queue->limits.discard_granularity = 0;
blk_queue_max_discard_sectors(disk->queue, 0);
blk_queue_max_segment_size(disk->queue, UINT_MAX);
blk_queue_max_segments(disk->queue, USHRT_MAX);
blk_queue_max_hw_sectors(disk->queue, 65536);
disk->queue->limits.max_sectors = 256;
mutex_init(&nbd->config_lock);
refcount_set(&nbd->config_refs, 0);
/*
* Start out with a zero references to keep other threads from using
* this device until it is fully initialized.
*/
refcount_set(&nbd->refs, 0);
INIT_LIST_HEAD(&nbd->list);
disk->major = NBD_MAJOR;
disk->first_minor = index << part_shift;
disk->minors = 1 << part_shift;
disk->fops = &nbd_fops;
disk->private_data = nbd;
sprintf(disk->disk_name, "nbd%d", index);
#add_disk中会发uevent通知让udev添加设备
err = add_disk(disk);
if (err)
goto out_free_work;
......
}
以上,nbd的初始化可以简单总结为:
- 注册block device
- 初始化netlink family
- 添加blk设备
其中,注册block device阶段,只是向major_names注册了name和major,到add_device阶段才是分配初始化nbd_device、gendisk这些,最后向userspace发uevent让udev添加设备
注:
1.以上也可以看出该怎么注册一个块设备呢?应该先register_blkdev注册主设备号和名字,然后再添加blk设备,初始化具体的device和gendisk等内容,最后再add gendisk的时候向udev发出uevent,让udev在userspace添加设备
2.major_names管理。major是0时,__register_blkdev函数中可以看到其实是从高到低遍历major_names数组去寻找空闲major的,这块是怎么管理的?在block/genhd.c中可以看到静态定义了一个blk_major_name指针数组,长度是BLKDEV_MAJOR_HASH_SIZE 255,这个blk_major_name中主要包含name major和blk_major_name指针。就是根据这个blk_major_name指针数组major_names去管理这些设备号的。但是我们很明显可以看到BLKDEV_MAJOR_MAX是512,那么这个255长度的数组怎么管理最大512个主设备号的呢?用hash来管理,可以看到major_to_index函数内容就是return major % BLKDEV_MAJOR_HASH_SIZE; 一般1-255的major号都已经有了指定的设备了,256-512是可以用作动态指定的。比如8号scsi设备和263都存储在major_names[8],其实就是搞了一个hash桶,把这512-1个设备号映射进255长度的major_names数组中,同一个hash桶中的元素通过链表来进行组织。
其实这块就有个疑问了,看__register_blkdev中是从512遍历到1的,如果256-512的major都已经被注册了,会不会去占用那些已经明确指定设备类型但是因为没有加载驱动就还没有注册的major号呢?如果使用的话,那该设备类型后续如果想要再注册是不是就不能注册了?后面做个实验试一下。
3.gendisk的作用。抽象了块设备,比如ssd、机械硬盘这些。其实,我理解就是相当于文件系统中VFS的作用,VFS提供了对实际使用的文件系统的更上一层的抽象,gendisk也是如此。比如VFS中的read write其实是最终其实是调用对应文件系统的read write去进行实际的读写,gendisk中的block_device_operations中也有一些submit_bio、open、release、poll_io、ioctl等函数指针,这些可想而知最终也是去调用对应的块设备驱动上去执行提交io等操作。另外,add_disk函数中会向udev发uevent,这个会通知uevent再/dev下创建设备。
4.这里还有个问题,很明显,可以看到在添加设备的时候,使用的是alloc_workqueue函数去申请workqueue,在我之前的认知中,workqueue那不就是通过kworker去做的工作嘛?但是我却在系统上看到了实实在在的nbd0-recv内核线程?为什么?原来是因为在alloc_workqueue的时候设置了WQ_MEM_RECLAIM,然后稍微追一下可以看到会调用init_rescuer函数,如果设置了WQ_MEM_RECLAIM,就使用wq的name创建一个专用的内核线程,而不是使用workqueue。为什么?可以看下WQ_MEM_RECLAIM = 1 << 3, /* may be used for memory reclaim */,也就是这种工作是有可能用于内存回收的,那为什么内存回收就不能使用kworker?因为容易形成死锁,首先,kworker执行的任务如果触发内存回收,那么谁会去回收内存呢?kworker会参与,比如脏页回写这些。所以kworker如果触发内存回收可能会与kworker本身造成死锁?
过程及原理
以spdk使用nbd为例,不过我不懂spdk,所以这块就大概看一下就好了,重点还是关注下nbd驱动的实现
首先spdk实现了一个start_nbd_disk的rpc,这个start_nbd_disk函数主要做的其实就是打开对应的nbd设备去ioctl设置相关内容,目前看spdk的start_nbd_disk函数会先后执行下面这几个ioctl
NBD_SET_BLKSIZE
NBD_SET_SIZE_BLOCKS
NBD_CLEAR_SOCK
NBD_SET_SOCK
NBD_SET_FLAGS
然后spdk会用pthread_create创建一个名为nbd_start_kernel的线程,这个线程去发一个NBD_DO_IT的ioctl
关闭连接和清理先不关注
所以去看下内核中这些ioctl实现了什么?
#内核中实际会调用到__nbd_ioctl
#NBD_SET_BLKSIZE实现
#实际上就是调用了nbd_set_size函数去设置了下nbd设备对应的nbd_device结构体的config中的bytesize和blksize_bits
#NBD_SET_SIZE_BLOCKS
#也是去调用nbd_set_size函数,上面那个是设置块大小,这个是传的块数量?
#NBD_CLEAR_SOCK
#调用nbd_clear_sock_ioctl,这里就是去清理socket
#nbd_add_socket
#这里绑定socket,这个函数的第二个参数arg传入的就是spdk创建的scoket的fd
static int nbd_add_socket(struct nbd_device *nbd, unsigned long arg,
bool netlink)
{
#获取socket
sock = nbd_get_socket(nbd, arg, &err);
#清理请求队列,确保重新绑定socket时候不会有错误请求
blk_mq_freeze_queue(nbd->disk->queue);
#若非netlink且没有task_setup且没有被bound,则设置task_setup
if (!netlink && !nbd->task_setup &&
!test_bit(NBD_RT_BOUND, &config->runtime_flags))
nbd->task_setup = current;
#若非netlink且(没有task_setup不是current或已经被bound),则设置跳出
if (!netlink &&
(nbd->task_setup != current ||
test_bit(NBD_RT_BOUND, &config->runtime_flags))) {
dev_err(disk_to_dev(nbd->disk),
"Device being setup by another task");
err = -EBUSY;
goto put_socket;
}
#分配nsock结构体
nsock = kzalloc(sizeof(*nsock), GFP_KERNEL);
#重新分配config socks内存,把新增的sock放进去
socks = krealloc(config->socks, (config->num_connections + 1) *
sizeof(struct nbd_sock *), GFP_KERNEL);
config->socks = socks;
nsock->fallback_index = -1;
nsock->dead = false;
mutex_init(&nsock->tx_lock);
nsock->sock = sock;
nsock->pending = NULL;
nsock->sent = 0;
nsock->cookie = 0;
socks[config->num_connections++] = nsock;
atomic_inc(&config->live_connections);
blk_mq_unfreeze_queue(nbd->disk->queue);
return 0;
put_socket:
blk_mq_unfreeze_queue(nbd->disk->queue);
sockfd_put(sock);
return err;
}
#NBD_DO_IT过程
nbd_start_device_ioctl
->nbd_start_device #启动设备
->set_bit(GD_NEED_PART_SCAN, &nbd->disk->state) #设置分区扫描标志
->wait_event_interruptible
->#上面wait_event_interruptible是等上面有事件中断的话,就关闭socket退出
#其中最主要的nbd_start_device函数为
static int nbd_start_device(struct nbd_device *nbd)
{
if (nbd->pid)
return -EBUSY;
if (!config->socks)
return -EINVAL;
#如果连接数大于1,但是却没有设置NBD_FLAG_CAN_MULTI_CONN,也就是不支持多连接
if (num_connections > 1 &&
!(config->flags & NBD_FLAG_CAN_MULTI_CONN)) {
dev_err(disk_to_dev(nbd->disk), "server does not support multiple connections per device.\n");
return -EINVAL;
}
#更新队列
blk_mq_update_nr_hw_queues(&nbd->tag_set, config->num_connections);
nbd->pid = task_pid_nr(current);
nbd_parse_flags(nbd);
#创建sysfs
error = device_create_file(disk_to_dev(nbd->disk), &pid_attr);
#设置NBD_RT_HAS_PID_FILE
set_bit(NBD_RT_HAS_PID_FILE, &config->runtime_flags);
#在debugfs下创建相关接口
nbd_dev_dbg_init(nbd);
#遍历每个连接,这里可能是由multi_conn的情况
for (i = 0; i < num_connections; i++) {
struct recv_thread_args *args;
args = kzalloc(sizeof(*args), GFP_KERNEL);
if (!args) {
sock_shutdown(nbd);
/*
* If num_connections is m (2 < m),
* and NO.1 ~ NO.n(1 < n < m) kzallocs are successful.
* But NO.(n + 1) failed. We still have n recv threads.
* So, add flush_workqueue here to prevent recv threads
* dropping the last config_refs and trying to destroy
* the workqueue from inside the workqueue.
*/
if (i)
flush_workqueue(nbd->recv_workq);
return -ENOMEM;
}
#给sk设置__GFP_MEMALLOC标志,确保内存紧张的时候也能分配内存
sk_set_memalloc(config->socks[i]->sock->sk);
#如果设置了timeout的话,就给queue也设置上
if (nbd->tag_set.timeout)
config->socks[i]->sock->sk->sk_sndtimeo =
nbd->tag_set.timeout;
atomic_inc(&config->recv_threads);
refcount_inc(&nbd->config_refs);
#初始化recv_work,并放入recv_workq队列
INIT_WORK(&args->work, recv_work);
args->nbd = nbd;
args->index = i;
queue_work(nbd->recv_workq, &args->work);
}
return nbd_set_size(nbd, config->bytesize, nbd_blksize(config));
}
#recv_work的过程如下
static void recv_work(struct work_struct *work)
{
#死循环
while (1) {
struct nbd_reply reply;
#读reply失败则退出
if (nbd_read_reply(nbd, args->index, &reply))
break;
#获取引用计数,防止出现use after free,且如果队列已经冻结了或没有inflight io则退出
if (!percpu_ref_tryget(&q->q_usage_counter)) {
dev_err(disk_to_dev(nbd->disk), "%s: no io inflight\n",
__func__);
break;
}
#处理IO
cmd = nbd_handle_reply(nbd, args->index, &reply);
#将PDU(protocol date unit)转换为rq
rq = blk_mq_rq_from_pdu(cmd);
if (likely(!blk_should_fake_timeout(rq->q))) {
bool complete;
#加锁,查看是否可以清楚inflight io状态
mutex_lock(&cmd->lock);
complete = __test_and_clear_bit(NBD_CMD_INFLIGHT,
&cmd->flags);
mutex_unlock(&cmd->lock);
#完成io
if (complete)
blk_mq_complete_request(rq);
}
#释放引用计数
percpu_ref_put(&q->q_usage_counter);
}
nsock = config->socks[args->index];
mutex_lock(&nsock->tx_lock);
nbd_mark_nsock_dead(nbd, nsock, 1);
mutex_unlock(&nsock->tx_lock);
nbd_config_put(nbd);
atomic_dec(&config->recv_threads);
#如果上面死循环退出了,唤醒recv_wq,也就是上面do_it后面执行wait_event_interruptible等待的,就是去处理退出
wake_up(&config->recv_wq);
kfree(args);
}
以上,过程可以总结为:
- 设置块设备,分区大小、分区数等
- 添加socket,放入nbd_device中的config->sock中去,此时前期准备完成了
- start_device,把recv_work加入队列中,也就是最开始初始化过程中的nbd0-recv线程。recv_work的作用就是一个死循环,接收远端的响应并处理
- start_device执行完,把recv_work加入队列后,就阻塞住了,wait_event_interruptible等待退出事件唤醒并处理(也就是上面的recv_work退出死循环的话会唤醒recv_wq)
注:
1.由此可见,nbd_device中的task_setup的作用是进行标记。也就是把执行set_socket的task作为setup的task,防止其他task在这个nbd_device上绑定socket?这个在https://patchwork.kernel.org/project/linux-block/patch/1481208755-24700-1-git-send-email-jbacik@fb.com/ 中也可见一斑。
2.好像没有涉及到之前初始化过程中的netlink?https://patchwork.kernel.org/project/linux-block/patch/1491512527-4286-6-git-send-email-jbacik@fb.com/ 在这可以看出,ioctl和netlink使用nbd设备的两种方式,netlink可扩展性强一些,而且解决了使用ioctl方式的线程在NBD_DO_IT ioctl时阻塞的问题(spdk这里也有注释,nbd_start_kernel这个线程在调用NBD_DO_IT ioctl后会一直阻塞,知道断开连接)。而spdk中为什么没使用netlink呢?一个可能是处于效率和简介性考虑?另一个出于兼容性考虑?毕竟ioctl要早很多,看netlink是17年才合入的。
3.为什么在nbd_add_socket要分别判断netlink、task_setup和NBD_RT_BOUND?使用其中一个不行嘛?看代码中那两处判断可以大致明白:netlink主要指示该任务是否是netlink发起,用于区分netlink和ioctl;task_setup是用于标记ioctl的,当其中一个task执行ioctl add scoket时候,设置task_setup防止其他线程抢占;而NBD_RT_BOUND是netlink用的,在nbd_genl_connect会设置这个标志位,表示这个设备已经被bound了,在ioctl的实现中也会去检查这个标志位,如果发现已经bound了,ioctl就不会执行了。所以,同一个nbd设备同一时间段只能被ioctl或netlink使用,不能两种方式混用?为什么ioctl和netlink的标志方式不同呢?deepseek解答了一波,很妙,因为ioctl是线程相关的且严格串行的,因此标志它的方式可以直接使用一个task_struct指针指向current;而netlink是异步的且线程无关,因此没办法使用task_struct指针,只能在flag上搞一个标志位了。
4.inflight IO到底干嘛的?查了一下,描述的是io到了驱动层,但是还没完成的一种状态。以nbd为例,执行nbd_queue_rq函数把rq入队的时候会set_bit置位NBD_CMD_INFLIGHT,然后在recv_work中将NBD_CMD_INFLIGHT清理掉,表示IO处理完成。
所以,理论上一次正常的nbd请求是怎样的呢?client读写请求->nbd驱动rq->封装通过socket发送到server->server处理->server返回->recv_work处理返回的响应
所以nbd模块的作用是什么?我觉得主要是这两点:1.提供了一个设备,在/dev下提供了nbd设备使server可以映射,使用户可以读写2.对nbd协议进行了封装,提供了读写设备的ops,通过ops可以封装用户的读写操作发送到server,提供了recv_work解析并处理server的返回
实验
如之前所看,在注册设备时,如果不指定major的话,会从高到低遍历查找一个可用的major。这时候会不会把预留的major给用上呢。做个实验试一下,写一个模块不指定major尝试循环注册512个设备,当然,肯定不可能全部注册,因为这时候已经有很多major被使用了,我想做的只是把剩余没使用的占满。
步骤如下:
1.先卸载nbd模块(当然也可以是其他模块)
2.加载test模块占领所有major
3.加载nbd模块
[root@XXX ~]# ll /dev/nbd*
ls: cannot access /dev/nbd*: No such file or directory
#insmod我写的模块,可以看到此时注册了200多设备
[root@XXX tmp]# dmesg |tail -20
[ 965.367037] register 221 start
[ 965.367038] register 221 end
[ 965.367039] register 222 start
[ 965.367040] register 222 end
[ 965.367041] register 223 start
[ 965.367041] register 223 end
[ 965.367042] register 224 start
[ 965.367043] register 224 end
[ 965.367043] register 225 start
[ 965.367044] register 225 end
[ 965.367045] register 226 start
[ 965.367046] register 226 end
[ 965.367046] register 227 start
[ 965.367047] register 227 end
[ 965.367048] register 228 start
[ 965.367049] register 228 end
[ 965.367049] register 229 start
[ 965.367050] register 229 end
[ 965.367051] register 230 start
[ 965.367051] __register_blkdev: failed to get major for test230
[root@XXX tmp]# modprobe nbd
modprobe: ERROR: could not insert 'nbd': Input/output error
果然,出现IO error了,因为在nbd模块里如果注册失败就是要返回-EIO
所以,如果模块没加载的话,大量注册major为0的随机major的设备,是会把这些设备号占用的,会导致真正使用该major的驱动加载失败
PS:刚开始用的kvm模块做实验,发现kvm模块能加载上。原因是kvm模块使用的的MISC_MAJOR字符设备major号,不止kvm在用,其他的一些东西也在用,所以我只把kvm模块卸载了,其他模块可能还在占用这个major号,所以我的test模块不会使用这个major号,所以kvm依旧能加载上。
后记
1.看一下当前的/dev/nbd*,可以看到每个nbd设备之间的次设备号隔了32
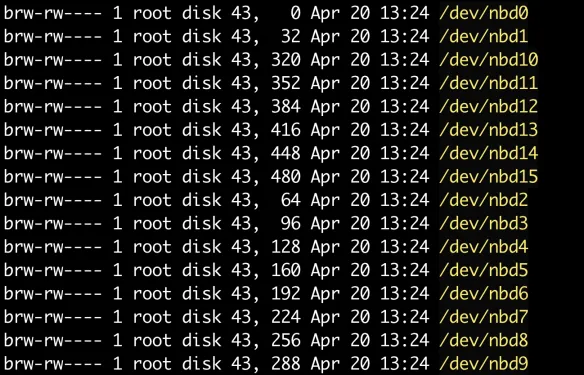
这是因为要给每个nbd设备的分区预留设备号,这个可以在nbd_dev_add函数中看到有disk->first_minor = index << part_shift;disk->minors = 1 << part_shift;这么一句。这里可能有点疑问,为什么max_part是16但是却预留32个次设备号呢?这是因为part_shift = fls(max_part);中寻找last bit的时候是从1开始数的,也就是数到16的那个bit是5。这样看上去也是合理的,因为first_minor通常是为整个设备使用的。所以是不是可以这么理解,虽然max_part是16,但是再加上用于整个设备的first_minor,实际上是是需要17个次设备号的。
2.nbd协议
https://github.com/NetworkBlockDevice/nbd/blob/master/doc/proto.md
协议介绍有说,nbd的后端并不一定是块设备,也可能是一个文件,它主要关注的是一段字节以及对这段字节特定偏移的一些操作
所以理论上说,其实只要server端按照nbd协议实现,任何的块设备或者文件或者一段数据都可以,甚至可以nbd套nbd,一层一层套着玩
3.一个很奇怪的事
在上面的代码中可以看到,nbd驱动是在start_device的时候才去判断 NBD_FLAG_CAN_MULTI_CONN的,为什么这样?按理来说是不是在add_sock的时候就应该去判断是不是支持multi_conn了?如果不支持就应该在add_sock的时候拒绝,而省的在去krealloc然后延迟到start_device的时候再去判断?
这个可以看一下https://github.com/NetworkBlockDevice/nbd/blob/master/doc/proto.md 可能是因为nbd协议有一个协商的步骤吧,需要先建立连接,然后再去协商server端是否支持multi_conn这些特性?如果在add_sock的时候还没有协商是否支持multi_conn就拒绝了,实际上server事有可能支持的。果然,有些看似不合理的背后都是有他的原因的。
4.netlink的方式还没看
参考
https://github.com/NetworkBlockDevice/nbd/blob/master/doc/proto.md
后后记
发现个事,我是使用云文档来写这些东西的。当我使用两个设备编辑这篇内容的时候。比如在mac上对文章进行了修改,我的台式机上能近乎实时检测到内容的改变,什么原理呢?类似inotify,fanotify?
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 857879363@qq.com