背景
众所周知,signal是linux内核中一种重要的异步通信机制,没有signal,我们可能很难打断一个进程的执行。
接下来我们带着一些问题去看signal相关的内容:
- 信号怎么发送的?
- 信号怎么处理的?
- 为什么D进程不响应信号?
- 内核线程和用户线程的信号处理有什么区别吗?
学习
- 当ctrl^C / kill时,内核发生了什么?
我们先开两个窗口,在其中一个窗口执行sleep 60,在另一个窗口上,strace一下这个进程,按下ctrl+C之后,我们可以发现,sleep进程被kill掉了,log显示是收到SIGINT被kill掉的
前台运行的进程可以直接ctrl^C打断,那后台运行的进程呢?我们一般使用kill [pid]命令。
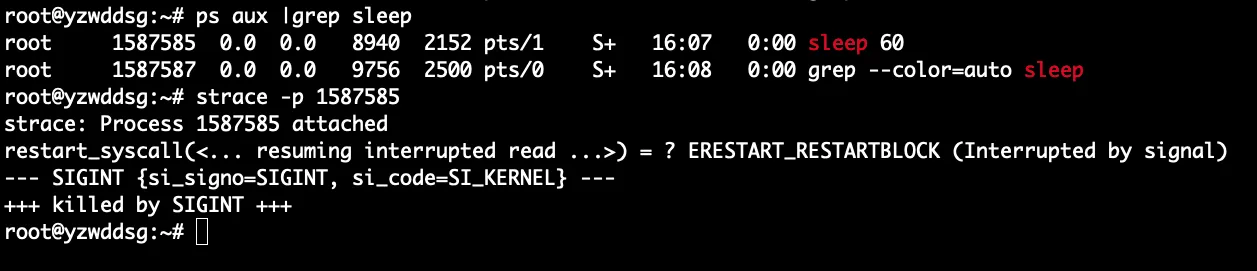
和上面一样,我们开启两个窗口。在其中一个窗口执行sleep 60 &创建一个后台进程,这时候会得到一个pid,然后strace这个pid。在另一个窗口执行kill [pid]去杀死这个进程,我们的strace结果就会得到下图所示的内容。可以看到这里是显示收到了SIGTERM信号而把进程kill掉了。

同理,可以试一下我们平时常用的kill -9,其实是收到SIGKILL信号。还可以尝试ctrl^Z、kill -6等其他常用的操作/命令,看看它们接受到的是什么信号。
那么内核中都有哪些信号呢?区别是什么?
在include/uapi/asm-generic/signal.h中可以定义了很多信号,一般常见的有以下几种:
| 信号 | 备注 |
|---|---|
| SIGHUP | 终端退出的hangup信号。在一个终端的开一个进程,当我们关闭这个终端时,运行的这个进程就会因为收到SIGHUP信号而退出。我们可以通过nohup命令来使当前的进程不响应SIGHUP信号。 |
| SIGINT | 一般是ctrl^C发出的让进程中断的信号。 |
| SIGKILL | 强制杀死进程的信号,不可以被捕获、忽略、自定义注册信号。kill -9可以触发 |
| SIGSEGV | 段错误信号。 |
| SIGTERM | 杀死进程,可以自定义信号处理方式。kill命令发送的信号。 |
| SIGCHLD | 子进程状态改变,向父进程进行通知的信号。 |
| SIGCONT | 继续执行的信号。 |
| SIGSTOP | 停止执行的信号,不可以被捕获、忽略、自定义注册信号。 |
| SIGTSTP | 暂停执行的信号,一般是ctrl^Z触发。 |
- 信号的发送
之前说到,ctrl^C和kill命令实际上都是给目标进程发送了信号,那么这个过程是怎么样的呢?
先来看一下kill命令的过程,直接看syscall的函数,调用关系如下
SYSCALL_DEFINE2(kill, pid_t, pid, int, sig)
->kill_something_info
->kill_proc_info
->kill_pid_info
->kill_pid_info_type
->group_send_sig_info
->do_send_sig_info
->send_signal_locked
->__send_signal_locked
static int __send_signal_locked(int sig, struct kernel_siginfo *info,
struct task_struct *t, enum pid_type type, bool force)
{
.......
//这里会进行一些特殊操作:
//1:如果目标进程的signal->flags中已经有SIGNAL_GROUP_EXIT了,返回false。因为现在目标进程已经在退出了
//2:如果是停止类信号(具体定义可见SIG_KERNEL_STOP_MASK),就将目标进程组中的所有SIGCONT信号flush掉
//3:如果是SIGCONT,则将目标进程组中的所有的SIG_KERNEL_STOP_MASK的信号flush掉,然后尝试唤醒目标进程
if (!prepare_signal(sig, t, force))
goto ret;
//如果是PIDTYPE_PID类型,也就是只针对线程,则获取线程对应的pending。如果不是只针对线程,则获取t->signal->shared_pending共享的pending
pending = (type != PIDTYPE_PID) ? &t->signal->shared_pending : &t->pending;
//如果是标准信号且该信号已经在目标进程的的pending上了,则直接返回
if (legacy_queue(pending, sig))
goto ret;
......
//如果是SIGKILL信号或者内核线程的话,跳过分配sigqueue的阶段。
//我认为是因为:1.SIGKILL就是直接立即让目标进程去处理并退出了2:内核线程不响应这些信号所以没必要
if ((sig == SIGKILL) || (t->flags & PF_KTHREAD))
goto out_set;
......
//分配并填充sigqueue
q = sigqueue_alloc(sig, t, GFP_ATOMIC, override_rlimit);
if (q) {
//添加到目标进程的pending链表上
list_add_tail(&q->list, &pending->list);
......
}
out_set:
signalfd_notify(t, sig);
sigaddset(&pending->signal, sig); //把sig信号添加到目标进程的pendingset中
complete_signal(sig, t, type); //调用signal_wake_up(这里会设置task的TIF_SIGPENDING)->kick_process->smp_send_reschedule
ret:
trace_signal_generate(sig, info, t, type != PIDTYPE_PID, result);
return ret;
}
再看一下ctrl^C中断的过程,过程应该如下,应该是tty终端驱动接收了这些字符:
static struct tty_ldisc_ops n_tty_ops = {
.......
.receive_buf = n_tty_receive_buf,
.write_wakeup = n_tty_write_wakeup,
.receive_buf2 = n_tty_receive_buf2,
.lookahead_buf = n_tty_lookahead_flow_ctrl,
};
n_tty_receive_buf
->n_tty_receive_buf_common
->__receive_buf
->n_tty_receive_buf_standard
->n_tty_receive_char_special
static void n_tty_receive_char_special(struct tty_struct *tty, u8 c,
bool lookahead_done)
{
......
if (L_ISIG(tty)) {
if (c == INTR_CHAR(tty)) {
n_tty_receive_signal_char(tty, SIGINT, c);
return;
}
static void
n_tty_receive_signal_char(struct tty_struct *tty, int signal, u8 c)
{
isig(signal, tty);
......
}
static void __isig(int sig, struct tty_struct *tty)
{
struct pid *tty_pgrp = tty_get_pgrp(tty);
if (tty_pgrp) {
kill_pgrp(tty_pgrp, sig, 1);
put_pid(tty_pgrp);
}
}
再继续追kill_pgrp的话就会发现,最后会调用到do_send_sig_info,就是走上面的发送signal的流程了。
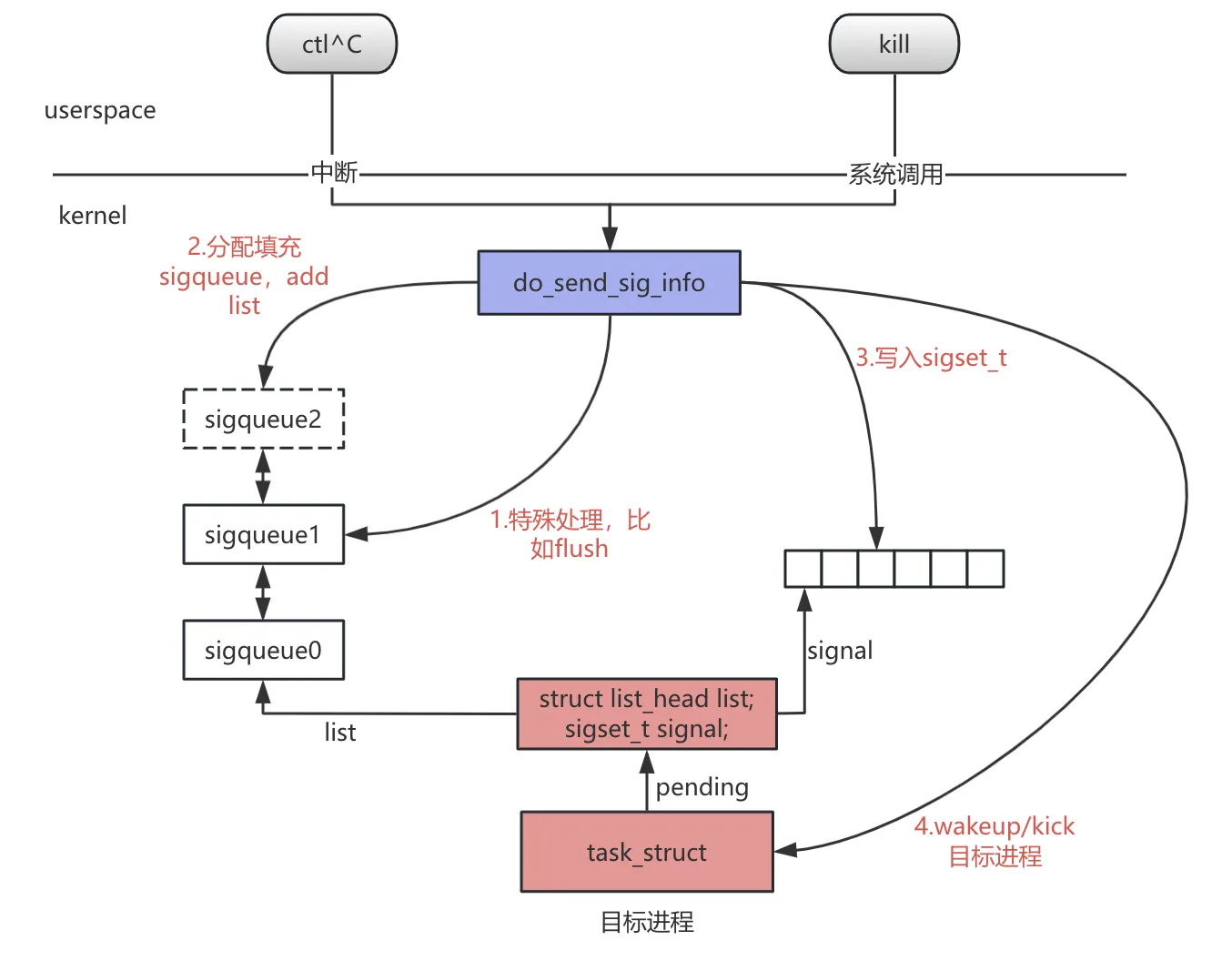
所以一个信号发送流程可以简化如下:
- 接收信号的处理
不管是用户敲键盘触发中断还是使用kill命令调用系统调用,最终的结果都是把信号挂到目标进程的pending上了。那么目标进程是怎么处理的呢?
处理过程如下:
//X86为例
__exit_to_user_mode_loop //进程从内核态返回用户态
->arch_do_signal_or_restart //如果设置了_TIF_SIGPENDING | _TIF_NOTIFY_SIGNAL
->get_signal //获取信号
->handle_signal //如果有用户自定义的handler,设置相关寄存器跳转执行自定义函数
其实主要看一下get_signal的过程:
bool get_signal(struct ksignal *ksig)
{
struct sighand_struct *sighand = current->sighand;
struct signal_struct *signal = current->signal;
int signr;
.......
relock:
spin_lock_irq(&sighand->siglock);
......
for (;;) {
struct k_sigaction *ka;
enum pid_type type;
//如果目标进程组正在exit或者有线程正在执行exec(正在执行exec为什么需要sigkill?因为正在执行exec需要把其他kill掉,新开一篇文章说一下)
//则设置信号为SIGKILL,然后从pending set中删掉SIGKILL重新计算pending并跳转到fatal,其实fatal就是主要去执行do_group_exit去exit了
if ((signal->flags & SIGNAL_GROUP_EXIT) ||
signal->group_exec_task) {
signr = SIGKILL;
sigdelset(¤t->pending.signal, SIGKILL);
trace_signal_deliver(SIGKILL, SEND_SIG_NOINFO,
&sighand->action[SIGKILL-1]);
recalc_sigpending();
goto fatal;
//判断jobctrl frozen等情况的处理
type = PIDTYPE_PID;
//优先dequeue同步信号,见SYNCHRONOUS_MASK,即段错误、bus error等错误需要立即处理的同步信号
signr = dequeue_synchronous_signal(&ksig->info);
//若没有同步信号,才需要从队列中去取出信号,规则是从低到高遍历未block的信号
//如果有设置了pending set的信号,则去queue中取出对应的signal
if (!signr)
signr = dequeue_signal(¤t->blocked, &ksig->info, &type);
if (!signr)
break; /* will return 0 */
......
//取出action
ka = &sighand->action[signr-1];
trace_signal_deliver(signr, &ksig->info, ka);
//判断sa.sa_handler的值
//如果是SIG_IGN,则忽略
//如果不是SIG_DFL,则有用户自定义handler,设置用户函数指针,break,在后面的handle_signal中去处理
//剩下就是SIG_DFL,就是默认的处理
if (ka->sa.sa_handler == SIG_IGN) /* Do nothing. */
continue;
if (ka->sa.sa_handler != SIG_DFL) {
/* Run the handler. */
ksig->ka = *ka;
if (ka->sa.sa_flags & SA_ONESHOT)
ka->sa.sa_handler = SIG_DFL;
break; /* will return non-zero "signr" value */
}
//SIG_DFL处理,若是需要忽略的signal,continue
if (sig_kernel_ignore(signr)) /* Default is nothing. */
continue;
//SIG_DFL处理,处理停止类信号
if (sig_kernel_stop(signr)) {
if (signr != SIGSTOP) {
spin_unlock_irq(&sighand->siglock);
if (is_current_pgrp_orphaned())
goto relock;
spin_lock_irq(&sighand->siglock);
}
if (likely(do_signal_stop(signr))) {
/* It released the siglock. */
goto relock;
}
continue;
}
fatal:
spin_unlock_irq(&sighand->siglock);
if (unlikely(cgroup_task_frozen(current)))
cgroup_leave_frozen(true);
current->flags |= PF_SIGNALED;
//SIG_DFL处理,产生core dump的信号处理
if (sig_kernel_coredump(signr)) {
if (print_fatal_signals)
print_fatal_signal(signr);
proc_coredump_connector(current);
vfs_coredump(&ksig->info);
}
/*
* PF_USER_WORKER threads will catch and exit on fatal signals
* themselves. They have cleanup that must be performed, so we
* cannot call do_exit() on their behalf. Note that ksig won't
* be properly initialized, PF_USER_WORKER's shouldn't use it.
*/
if (current->flags & PF_USER_WORKER)
goto out;
//SIG_DFL处理,其他杀死进程的信号处理
do_group_exit(signr);
/* NOTREACHED */
}
spin_unlock_irq(&sighand->siglock);
ksig->sig = signr;
if (signr && !(ksig->ka.sa.sa_flags & SA_EXPOSE_TAGBITS))
hide_si_addr_tag_bits(ksig);
out:
return signr > 0;
}
以上,我们可以看到,其实接收信号的主要处理过程可以简要概括如下:
- 处理特殊状态。如果目标进程组已经处于SIGNAL_GROUP_EXIT或其他特殊状态,先处理
- 取同步信号
- (若无同步信号被取出)按照信号号从低到高遍历取出一个未被block的信号
- 判断取出信号的current->sighand.action[signr-1].sa._sa_handler的值:如果SIG_IGN,则忽略;如果非SIG_DFL,则跳转到用户自定义handler;SIG_DFL,则按照信号类型进行处理。
如上,可以看到接收和处理信号的过程中分了好多类型,总结如下:
| 信号类型 | 信号 | 备注 |
|---|---|---|
| 标准信号 | 停止信号(SIG_KERNEL_STOP_MASK):SIGSTOP、SIGTSTP、SIGTTIN、SIGTTOU | |
| 忽略类信号(SIG_KERNEL_IGNORE_MASK):SIGCONT、SIGCHLD、SIGWINCH、SIGURG | SIGCONT在信号处理过程中将忽略,这个信号主要在信号发送流程起作用 | |
| core dump类信号(SIG_KERNEL_COREDUMP_MASK):SIGQUIT、SIGILL、SIGTRAP、SIGABRT、SIGFPE、SIGSEGV、SIGBUS、SIGSYS、SIGXCPU、SIGXFSZ | 产生core_dump | |
| 其他信号 | 直接导致进程组exit | |
| 实时信号 | SIGRTMIN <= signr < SIGRTMAX的信号 | 与标准信号的最大区别在于:标准信号在sigqueue中只能存在一个,而实时信号可以存在多个,fifo排队处理(在上面的__send_signal_locked函数中可以体现出来,判断如果legacy_queue直接goto ret了,而实时信号可以继续入队)Note that SIGRTMIN is often blocked, so it is better to use (at least) SIGRTMIN + 1. |
除此之外,标准信号还可以分为同步信号和其他信号,同步信号(SYNCHRONOUS_MASK)有SIGSEGV、SIGBUS、SIGILL、SIGTRAP、SIGFPE、SIGSYS,指因为指令异常或者其他异常情况需要同步处理的信号。
为了更直观地感知信号处理过程中这些数据结构直接的关系,我们找一个vmcore来看一下:
crash> task_struct.signal,sighand,blocked,real_blocked,saved_sigmask,pending ffff99fd8a730000
signal = 0xffff99fd9258e780,
sighand = 0xffff99fd91d439c0,
blocked = {
sig = {0}
},
real_blocked = {
sig = {0}
},
saved_sigmask = {
sig = {0}
},
pending = {
list = { //sigqueue链表
next = 0xffff99fd8a730c10,
prev = 0xffff99fd8a730c10
},
signal = { //pending set
sig = {0}
}
},
crash> sighand_struct 0xffff99fd91d439c0
......
action = {{
sa = {
sa_handler = 0x452e70, //自定义handler函数地址
sa_flags = 67108864,
sa_restorer = 0x7f2a45236400,
sa_mask = {
sig = {1132494587}
}
}
}, {
sa = {
sa_handler = 0x453100, //自定义handler函数地址
sa_flags = 67108864,
sa_restorer = 0x7f2a45236400,
sa_mask = {
sig = {0}
}
}
}, {
sa = {
sa_handler = 0x1, //SIG_IGN
sa_flags = 67108864,
sa_restorer = 0x7f2a45236400,
sa_mask = {
sig = {0}
}
}
}, {
......
}, {
sa = {
sa_handler = 0x0, //SIG_DFL
sa_flags = 0,
sa_restorer = 0x0,
sa_mask = {
sig = {0}
}
}
.......
- 信号的处理时机
上面已经可以看出,信号的检查和处理主要发生在从内核态返回用户态之前。
所以这里也就可以知道,为什么D进程不响应信号?因为D进程在等IO或者等什么其他资源,不会走到运行态,不存在内核态到用户态的过程,因此也就没有响应并处理信号的时机。
除此之外,看上面的信号发送和处理过程,还可以想到,哪些情况下不能响应信号呢?
- 进程一直在内核态执行,不返回用户态。比如softlockup了
- 信号被屏蔽
- 目标进程正在exit
- ……
那么,如果我把nohz打开,然后再用户态起一个死循环进程,进程还能立即响应信号嘛?

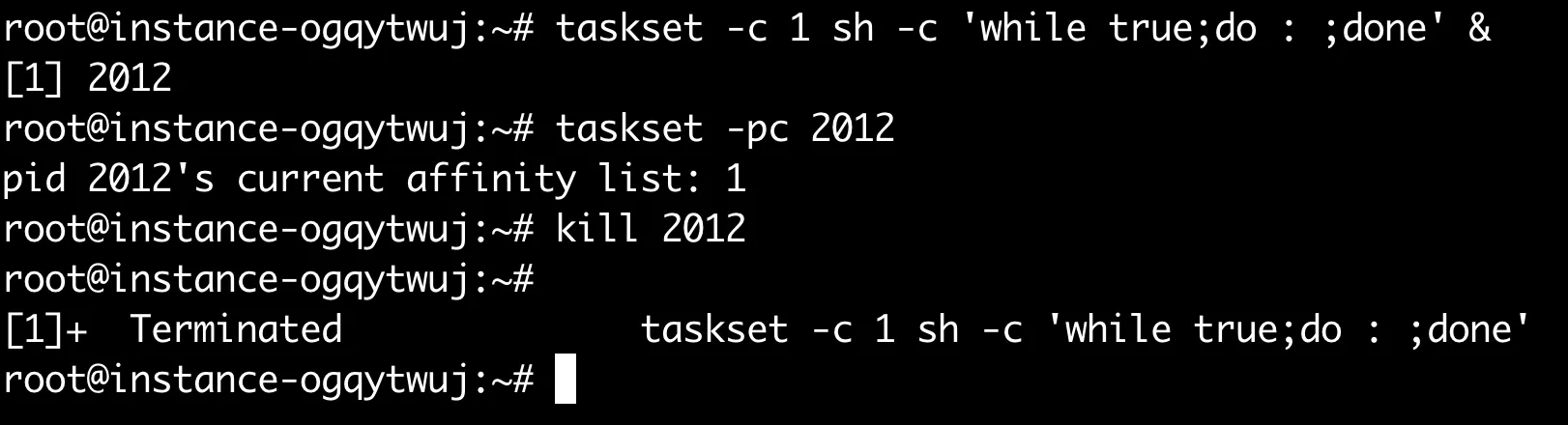
可以kill掉,为什么?
其实答案还是在发送信号的__send_signal_locked函数中,在complete_signal中我们可以看到,首先会尝试通过wake_up_state去唤醒进程(这里针对的就是没有在运行的进程,wake_up过程中自然就有机会让目标进程响应信号),如果进程在别的cpu上正在运行,则kick_process触发该cpu的重新调度(这样也有机会让目标进程进行调度去响应信号)。至于目标进程正在该cpu上运行的情况,一般情况下,一个进程给自己发什么信号呢?如果内部调用kill之类的函数,则系统调用进入kernel然后返回userspace的时候会触发信号响应了。
- 为什么SIGKILL和SIGSTOP不能自定义
可以猜测,内核至少要保留一些能让进程停止或退出的信号不被hook,这个应该是合理的。
那内核是怎么做的呢?
#define SIG_KERNEL_ONLY_MASK (\
rt_sigmask(SIGKILL) | rt_sigmask(SIGSTOP))
#define sig_kernel_only(sig) siginmask(sig, SIG_KERNEL_ONLY_MASK)
//发送信号时,ignore SIG_KERNEL_ONLY_MASK信号
__send_signal_locked
->prepare_signal
->sig_ignored
->sig_task_ignored
static bool sig_task_ignored(struct task_struct *t, int sig, bool force)
{
......
/* SIGKILL and SIGSTOP may not be sent to the global init */
if (unlikely(is_global_init(t) && sig_kernel_only(sig)))
return true;
if (unlikely(t->signal->flags & SIGNAL_UNKILLABLE) &&
handler == SIG_DFL && !(force && sig_kernel_only(sig)))
return true;
//即使unkillable的线程也要响应SIG_KERNEL_ONLY_MASK信号
bool get_signal(struct ksignal *ksig)
{
......
if (unlikely(signal->flags & SIGNAL_UNKILLABLE) &&
!sig_kernel_only(signr))
continue;
//禁止对SIG_KERNEL_ONLY_MASK信号信号注册自定义handler
rt_sigaction/sigaction/signal(syscall)
->do_sigaction
int do_sigaction(int sig, struct k_sigaction *act, struct k_sigaction *oact)
{
.......
if (!valid_signal(sig) || sig < 1 || (act && sig_kernel_only(sig)))
return -EINVAL;
- 内核线程对信号的处理
我们从一段core开始
crash> set 2
PID: 2
COMMAND: "kthreadd"
TASK: ffff99fd8037c000 [THREAD_INFO: ffff99fd8037c000]
CPU: 54
STATE: TASK_INTERRUPTIBLE
crash> task_struct.signal,sighand,blocked,real_blocked,saved_sigmask,pending ffff99fd8037c000
signal = 0xffff99fd81710480,
sighand = 0xffff99fd81708840,
blocked = {
sig = {0}
},
real_blocked = {
sig = {0}
},
saved_sigmask = {
sig = {0}
},
pending = {
list = {
next = 0xffff99fd8037cc10,
prev = 0xffff99fd8037cc10
},
signal = {
sig = {0}
}
},
crash_v804> sighand_struct 0xffff99fd81708840 |grep sa_handler //所有handler都是SIG_IGN
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
sa_handler = 0x1,
crash>
以上可以看出,内核线程的所有sa_handler都是SIG_IGN,这个过程在threadd内核线程创建的时候,后面所有的内核线程都fork自kthreadd,所以所有的内核线程的所有sa_handler都是SIG_IGN
int kthreadd(void *unused)
{
.......
ignore_signals(tsk);
void ignore_signals(struct task_struct *t)
{
int i;
for (i = 0; i < _NSIG; ++i)
t->sighand->action[i].sa.sa_handler = SIG_IGN;
flush_signals(t);
}
然后我们看kernel/signal.c中的代码,发现对内核线程的特殊处理,并没有明显的直接禁止向内核线程发送信号/禁止内核线程接收信号!
static bool sig_task_ignored(struct task_struct *t, int sig, bool force)
{
.......
if (unlikely((t->flags & PF_KTHREAD) &&
(handler == SIG_KTHREAD_KERNEL) && !force))
return true;
//只是在判断SIGKILL和目标线程是内核线程的时候,不创建sigqueue,并没有直接禁止向内核线程发送信号!
static int __send_signal_locked(int sig, struct kernel_siginfo *info,
struct task_struct *t, enum pid_type type, bool force)
{
......
if ((sig == SIGKILL) || (t->flags & PF_KTHREAD))
goto out_set;
如此说来,内核线程是可能可以响应信号的(如果内核线程不能响应信号,为什么要把信号处理的相关结构体放到task_struct中,而不是去区分用户线程和内核线程,为什么内核线程还要有这些结构体,从这里也应该可以猜测处内核线程是可以处理信号的吧)
#define SIG_KTHREAD ((__force __sighandler_t)2)
#define SIG_KTHREAD_KERNEL ((__force __sighandler_t)3)
//允许内核线程处理某个信号,包括userspace和kernel发出的
static inline void allow_signal(int sig)
{
/*
* Kernel threads handle their own signals. Let the signal code
* know it'll be handled, so that they don't get converted to
* SIGKILL or just silently dropped.
*/
kernel_sigaction(sig, SIG_KTHREAD);
}
//允许内核线程处理某个信号,只处理来自kernel的信号
static inline void allow_kernel_signal(int sig)
{
/*
* Kernel threads handle their own signals. Let the signal code
* know signals sent by the kernel will be handled, so that they
* don't get silently dropped.
*/
kernel_sigaction(sig, SIG_KTHREAD_KERNEL);
}
static inline void disallow_signal(int sig)
{
kernel_sigaction(sig, SIG_IGN);
}
所以我们可以看到不少驱动的内核线程里可以通过以上哪些函数设置是否允许某个signal被响应
1 659 drivers/isdn/mISDN/l1oip_core.c <<l1oip_socket_thread>>
allow_signal(SIGTERM);
2 8487 drivers/md/md.c <<md_thread>>
allow_signal(SIGKILL);
3 4102 drivers/net/wireless/broadcom/brcm80211/brcmfmac/sdio.c <<brcmf_sdio_watchdog_thread>>
allow_signal(SIGTERM);
4 385 drivers/staging/rtl8723bs/core/rtw_cmd.c <<rtw_cmd_thread>>
allow_signal(SIGTERM);
5 2492 drivers/staging/rtl8723bs/core/rtw_xmit.c <<rtw_xmit_thread>>
allow_signal(SIGTERM);
6 409 drivers/staging/rtl8723bs/hal/rtl8723bs_xmit.c <<rtl8723bs_xmit_thread>>
allow_signal(SIGTERM);
需要注意,内核线程肯定是没有内核态->用户态这个过程的,因此内核线程的信号处理时机与用户进程是不同的,内核线程需要自己维护pending的检查
当然,也许更常用的内核线程之间的停止机制是:kthread_should_stop和kthread_stop
小实验
从一个例子开始,测试对SIGINT自定义信号处理函数,并屏蔽SIGTERM信号
#include <stdio.h>
#include <signal.h>
#include <string.h>
void yzwddsg_handle_int(int signum) {
printf("haha, hook %d\n", signum);
}
int main()
{
struct sigaction act_int, act_term;
memset(&act_int, 0, sizeof(act_int));
act_int.sa_handler = &yzwddsg_handle_int;
sigaction(SIGINT, &act_int, NULL);
memset(&act_term, 0, sizeof(act_term));
act_term.sa_handler = SIG_IGN;
sigaction(SIGTERM, &act_term, NULL);
while(1) {
;
}
return 0;
}
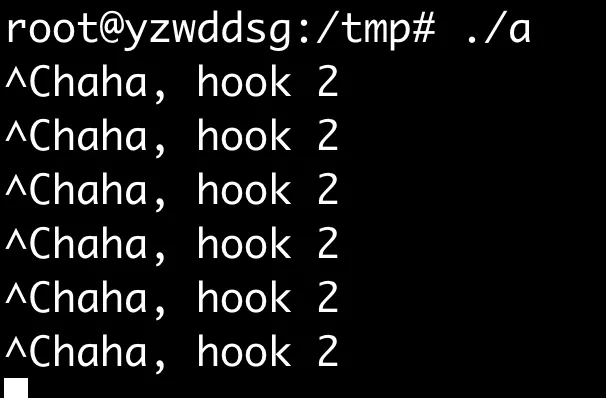
ctrl+C已经被hook,没法停止程序
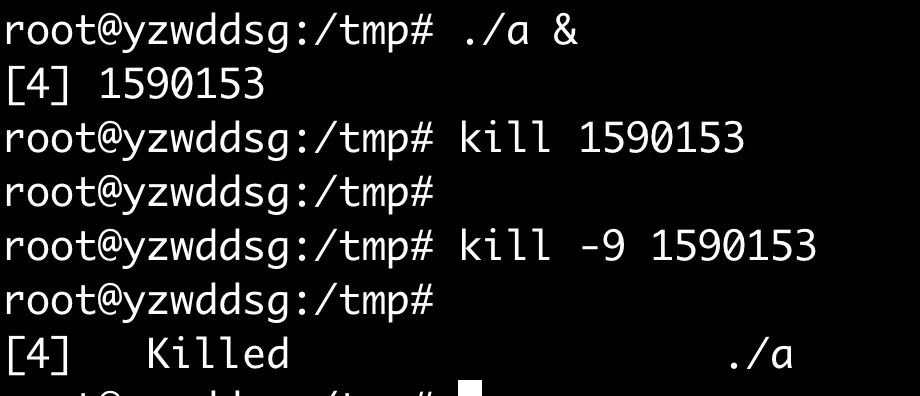
kill也被忽略,kill -9才能杀死
尝试把对SIGTERM换成SIGKILL
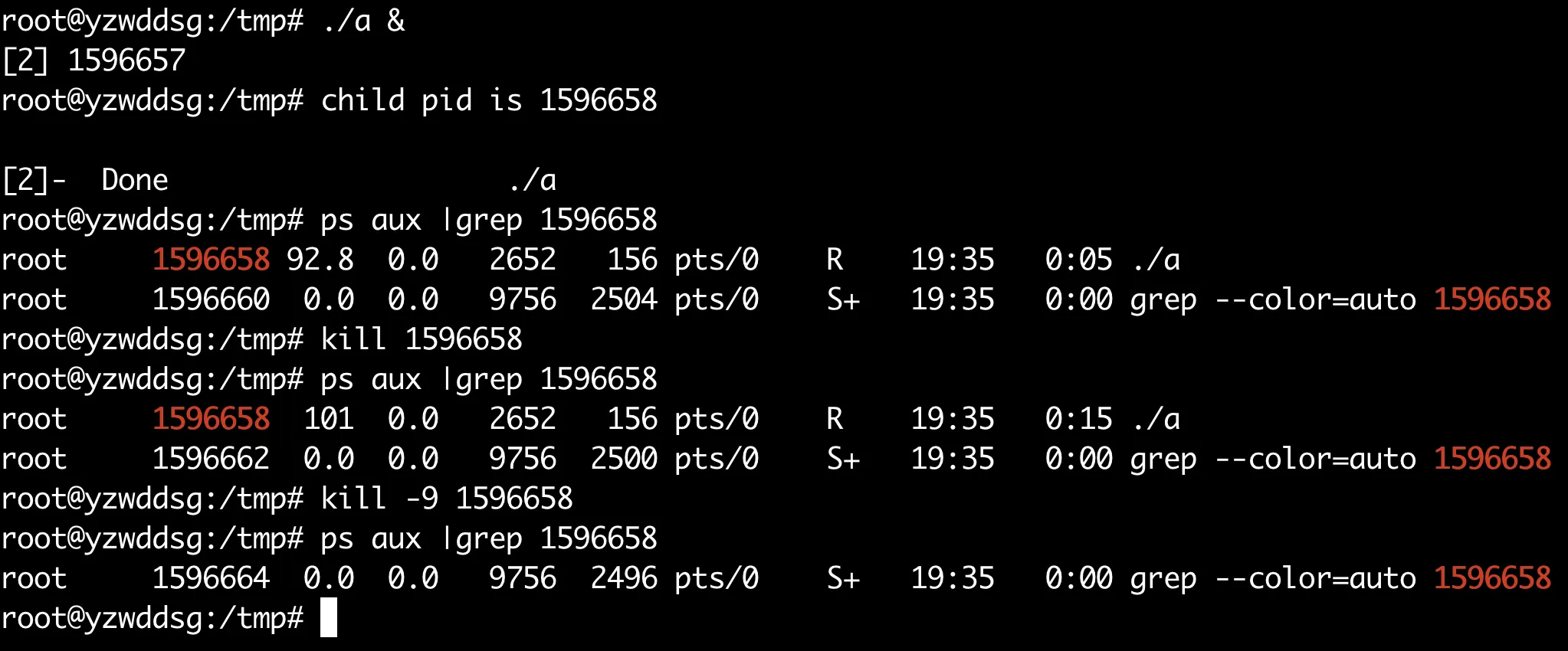
进程依然可以被kill -9杀死,如果检查sigaction的返回值的话可以看到其实返回的是-1,也就是系统调用给SIGKILL设置自定义handler失败了
那么,fork子进程是不是继承了父进程的handler呢?
修改一下代码
#include <stdio.h>
#include <signal.h>
#include <string.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
void yzwddsg_handle_int(int signum) {
printf("haha, hook %d\n", signum);
}
int main()
{
struct sigaction act_int, act_term;
pid_t child;
memset(&act_int, 0, sizeof(act_int));
act_int.sa_handler = &yzwddsg_handle_int;
sigaction(SIGINT, &act_int, NULL);
memset(&act_term, 0, sizeof(act_term));
act_term.sa_handler = SIG_IGN;
sigaction(SIGTERM, &act_term, NULL);
child = fork();
if (child == 0) {
while(1) {}
} else {
printf("child pid is %d\n", child);
exit(0);
}
return 0;
}
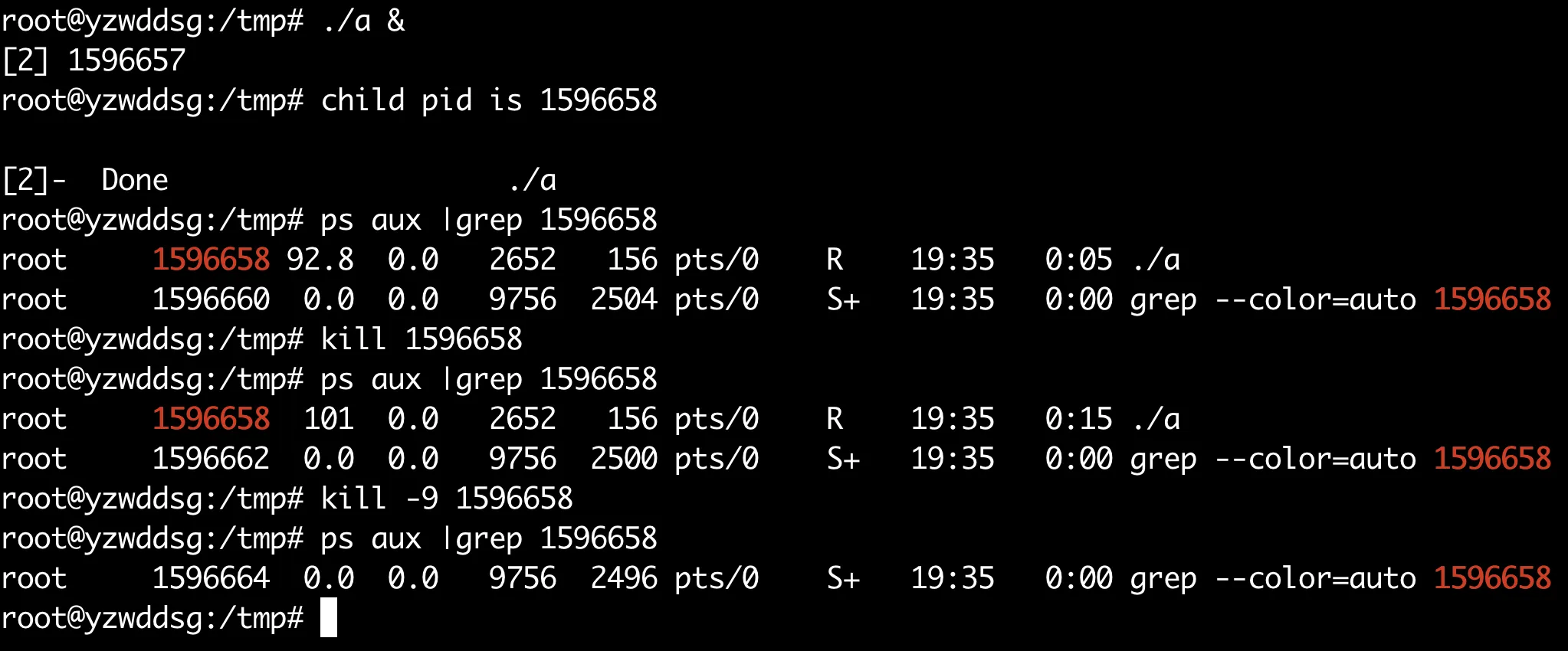
可以看到fork出来的子进程1596658是继承了自定义handler的,kill命令并不能杀死它
后记
- 注意到get_signal中,判断目标进程如果是SIGNAL_GROUP_EXIT或group_exec_task就走SIGKILL信号去处理,group_exec_task是怎么个意思?下面再开一篇文章看看吧
- 最后,提个小问题,上面可以看到,SIG_KTHREAD和SIG_KTHREAD_KERNEL分别是2和3,那么如果我写一个用户程序,把sa_handler赋值为(void *)0x2或者(void *)0x3,那么在处理信号get_signal中难道就直接认为是内核态的信号处理流程了嘛?答案就在上面的内容中了。
最后的最后:祝大家新年快乐,万事大吉,天天开心
11st
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 857879363@qq.com