背景
隔壁组同学遇到个问题让排查一下,说是df -h和du -h显示的磁盘容量是不同的。
具体表现为,du -sh /根分区看到的磁盘使用量是28G,而df -h /看到的磁盘使用量是369G,差了300多G,于是需要排查这消失的300多G去了哪里呢?
root@xxxxxxx:~# du -sh /
28G /
root@xxxxxxx:~# df -h /
/dev/vda2 492G 368G 104G 78% /
这里就介绍下这个问题的排查过程,然后借此机会看一下df和du命令的底层实现。
问题排查过程
看到这种,首先肯定想到是不是有文件已经删掉了但是fd没有释放呢?
lsof |grep deleted看一下,确实有一些fd没释放
root@xxxxxxx:/# lsof |grep deleted
xxx 1038387 1038390 xxx root 112u REG 0,27 10488584 3 /dev/shm/skynet_shared_memory (deleted)
xxx 1038387 1038391 xxx root 112u REG 0,27 10488584 3 /dev/shm/skynet_shared_memory (deleted)
xxx 1038387 1038392 xxx root 112u REG 0,27 10488584 3 /dev/shm/skynet_shared_memory (deleted)
xxx 1038387 1038393 xxx root 112u REG 0,27 10488584 3 /dev/shm/skynet_shared_memory (deleted)
xxx 1038387 1038394 xxx root 112u REG 0,27 10488584 3 /dev/shm/skynet_shared_memory (deleted)
......
但是马上就可以排除这些,首先每个文件大小才10M,算下来远远达不到消失的300多G那么多,另外,看路径可以知道,这是个tmpfs,在内存中的,不占用磁盘空间。
所以绝对不可能是这些fd没释放导致的问题。
查看history发现有人执行过一个脚本,是一个mount nvme盘的脚本。发现这个脚本mount /ssd到nvme盘了。那猜测应该就是/ssd下原本就有内容,然后还强行mount /ssd到nvme盘上,导致挂载点覆盖了。
然后把现在的/ssd挂载点umount掉,看一下果然原本就有/ssd这个目录,数据大小为300多G。删掉这里的内容之后重新mount /ssd到nvme设备就好了。
df命令的实现
strace df -h /看一下df命令实际上是调用了什么呢?
......
statfs("/", {f_type=EXT2_SUPER_MAGIC, f_bsize=4096, f_blocks=111101586, f_bfree=105525587, f_bavail=105521491, f_files=57376768, f_ffree=57142542, f_fsid={1398045837, 701130627}, f_namelen=255, f_frsize=4096, f_flags=ST_VALID|ST_RELATIME}) = 0
......
可以看到,其实df命令最终就是通过statfs系统调用来获取的磁盘容量等内容,那么我们看一下statfs系统调用过程。
//首先statfs是super_operations中的一个函数指针结构体,所以实际上每个文件系统都有他自己的statfs函数
//我们当前使用的是ext4文件系统,所以实际上调用的是ext4_statfs
struct super_operations {
......
int (*statfs)(struct dentry *dentry, struct kstatfs *kstatfs);
static int ext4_statfs(struct dentry *dentry, struct kstatfs *buf)
{
struct super_block *sb = dentry->d_sb;
struct ext4_sb_info *sbi = EXT4_SB(sb);
struct ext4_super_block *es = sbi->s_es;
ext4_fsblk_t overhead = 0, resv_blocks;
s64 bfree;
resv_blocks = EXT4_C2B(sbi, atomic64_read(&sbi->s_resv_clusters));
if (!test_opt(sb, MINIX_DF))
overhead = sbi->s_overhead;
buf->f_type = EXT4_SUPER_MAGIC;
buf->f_bsize = sb->s_blocksize;
buf->f_blocks = ext4_blocks_count(es) - EXT4_C2B(sbi, overhead);
bfree = percpu_counter_sum_positive(&sbi->s_freeclusters_counter) -
percpu_counter_sum_positive(&sbi->s_dirtyclusters_counter);
/* prevent underflow in case that few free space is available */
buf->f_bfree = EXT4_C2B(sbi, max_t(s64, bfree, 0));
buf->f_bavail = buf->f_bfree -
(ext4_r_blocks_count(es) + resv_blocks);
if (buf->f_bfree < (ext4_r_blocks_count(es) + resv_blocks))
buf->f_bavail = 0;
buf->f_files = le32_to_cpu(es->s_inodes_count);
buf->f_ffree = percpu_counter_sum_positive(&sbi->s_freeinodes_counter);
buf->f_namelen = EXT4_NAME_LEN;
buf->f_fsid = uuid_to_fsid(es->s_uuid);
#ifdef CONFIG_QUOTA
if (ext4_test_inode_flag(dentry->d_inode, EXT4_INODE_PROJINHERIT) &&
sb_has_quota_limits_enabled(sb, PRJQUOTA))
ext4_statfs_project(sb, EXT4_I(dentry->d_inode)->i_projid, buf);
#endif
return 0;
}
可以看出来,df命令查看磁盘容量的过程其实就是去调用对应文件系统statfs函数获取super block(sb)中的一些信息,通过这些信息来计算磁盘容量等。
du命令的实现
那strace du -sh /来看一下du的执行过程,可以看到输出是很长的,能看到大致是在遍历/根分区下的每一级目录的每一个文件,然后执行如下过程:
getdents(4, /* 3 entries */, 32768) = 88
getdents(4, /* 0 entries */, 32768) = 0
close(4) = 0
newfstatat(6, "lastnotification", {st_mode=S_IFREG|0600, st_size=11, ...}, AT_SYMLINK_NOFOLLOW) = 0
close(6) = 0
close(5) = 0
newfstatat(3, ".lesshst", {st_mode=S_IFREG|0600, st_size=517, ...}, AT_SYMLINK_NOFOLLOW) = 0
newfstatat(3, "perf.data", {st_mode=S_IFREG|0600, st_size=3640779, ...}, AT_SYMLINK_NOFOLLOW) = 0
newfstatat(3, "nohup.out", {st_mode=S_IFREG|0600, st_size=244, ...}, AT_SYMLINK_NOFOLLOW) = 0
newfstatat(3, "bios.txt", {st_mode=S_IFREG|0644, st_size=305008, ...}, AT_SYMLINK_NOFOLLOW) = 0
newfstatat(3, "a.sh", {st_mode=S_IFREG|0644, st_size=39, ...}, AT_SYMLINK_NOFOLLOW) = 0
newfstatat(3, ".ssh", {st_mode=S_IFDIR|0700, st_size=4096, ...}, AT_SYMLINK_NOFOLLOW) = 0
openat(3, ".ssh", O_RDONLY|O_NOCTTY|O_NONBLOCK|O_DIRECTORY|O_NOFOLLOW) = 4
fcntl(4, F_GETFD) = 0
fcntl(4, F_SETFD, FD_CLOEXEC) = 0
fstat(4, {st_mode=S_IFDIR|0700, st_size=4096, ...}) = 0
fcntl(4, F_GETFL) = 0x38800 (flags O_RDONLY|O_NONBLOCK|O_LARGEFILE|O_DIRECTORY|O_NOFOLLOW)
fcntl(4, F_SETFD, FD_CLOEXEC) = 0
newfstatat(3, ".ssh", {st_mode=S_IFDIR|0700, st_size=4096, ...}, AT_SYMLINK_NOFOLLOW) = 0
基本上就是getdents获取获取dentry,然后newfstatat遍历所有文件的数据。如此进行递归遍历。
看一下newfstatat系统调用获取的是什么?大致过程如下:
newfstatat系统调用入口
->vfs_fstatat
->vfs_fstat(通过fd而非文件路径的方式)
->vfs_getattr
->ext4_file_getattr
->generic_fillattr
void generic_fillattr(struct mnt_idmap *idmap, u32 request_mask,
struct inode *inode, struct kstat *stat)
{
vfsuid_t vfsuid = i_uid_into_vfsuid(idmap, inode);
vfsgid_t vfsgid = i_gid_into_vfsgid(idmap, inode);
stat->dev = inode->i_sb->s_dev;
stat->ino = inode->i_ino;
stat->mode = inode->i_mode;
stat->nlink = inode->i_nlink;
stat->uid = vfsuid_into_kuid(vfsuid);
stat->gid = vfsgid_into_kgid(vfsgid);
stat->rdev = inode->i_rdev;
stat->size = i_size_read(inode);
stat->atime = inode_get_atime(inode);
......
}
可以看到,实际上就是根据fd/文件路径获取对应的inode,从inode中提取一些元数据信息。
小实验
- 进程持有删除的文件
//创建一个aaa文件,大小为1G
dd if=/dev/zero of=aaa bs=1M count=1024
//创建完成后,df和du命令的结果
[root@yzwddsg tmp]# df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 424G 23G 402G 6% /
[root@yzwddsg tmp]# du -sh /tmp
1.3G /tmp
//创建一个后台进程打开aaa(进入到另一个不同的目录下执行)
[root@yzwddsg /]# nohup tail -f /tmp/aaa &
[1] 314337
//删除aaa
[root@yzwddsg tmp]# rm -rf aaa
//再次执行df和du查看输出
[root@yzwddsg tmp]# df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 424G 24G 401G 6% /
[root@yzwddsg tmp]# du -sh /tmp
270M /tmp
进程持有fd时,du命令已经统计不到相关信息了,但是df命令中貌似还存在该文件的信息。
这里,删除aaa后,其实du看到的就已经没有了
但是df中还是有,并且多了2G而不是1G。这是因为,tail -f命令,第一,增加了一个nohup.out,这个占用了1G,另外,aaa的fd被持有,还有1G
- 稀疏文件
//创建一个稀疏文件
dd if=/dev/zero of=aaa bs=1M seek=1024 count=1
//分别ls、du和df看一下输出
[root@yzwddsg tmp]# ls -lh aaa
-rw-r--r-- 1 root root 1.1G Apr 7 16:58 aaa
[root@yzwddsg tmp]# df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 424G 22G 403G 6% /
[root@yzwddsg tmp]# du -sh /tmp
271M /tmp
稀疏文件,df和du命令都只统计了实际大小,而ls命令看到的是逻辑大小。
- 压缩文件
//创建一个10G大小的文件并查看du和df输出
[root@yzwddsg tmp]# dd if=/dev/zero of=aaa bs=1M count=10240
10240+0 records in
10240+0 records out
10737418240 bytes (11 GB) copied, 19.5824 s, 548 MB/s
[root@yzwddsg tmp]# du -sh /tmp
11G /tmp
[root@yzwddsg tmp]# df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 424G 32G 393G 8% /
//压缩文件并删除原始文件,然后查看df和du
[root@yzwddsg tmp]# tar zcvf aaa.tgz aaa
aaa
[root@yzwddsg tmp]# rm -rf aaa
[root@yzwddsg tmp]# ls -lh aaa.tgz
-rw-r--r-- 1 root root 10M Apr 7 17:13 aaa.tgz
[root@yzwddsg tmp]# du -sh /tmp
280M /tmp
[root@yzwddsg tmp]# df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 424G 22G 403G 6% /
最初创建10G文件,df和du的统计中都是增长了10G使用容量。压缩文件之后,du和df看到的都是压缩后的容量
- 软硬链接
//创建一个文件,大小为1G
dd if=/dev/zero of=aaa bs=1M count=1024
//在其他目录制作一个指向aaa文件的软链接,查看df和du输出
[root@yzwddsg tmp]# du -sh /tmp
1.3G /tmp
[root@yzwddsg tmp]# df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 424G 23G 402G 6% /
//在其他目录制作一个指向aaa文件的硬链接,查看df和du输出
[root@yzwddsg tmp]# du -sh /tmp/
1.3G /tmp/
[root@yzwddsg tmp]# df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 424G 23G 402G 6% /
总结
- 所以df命令和du命令的区别是什么呢?
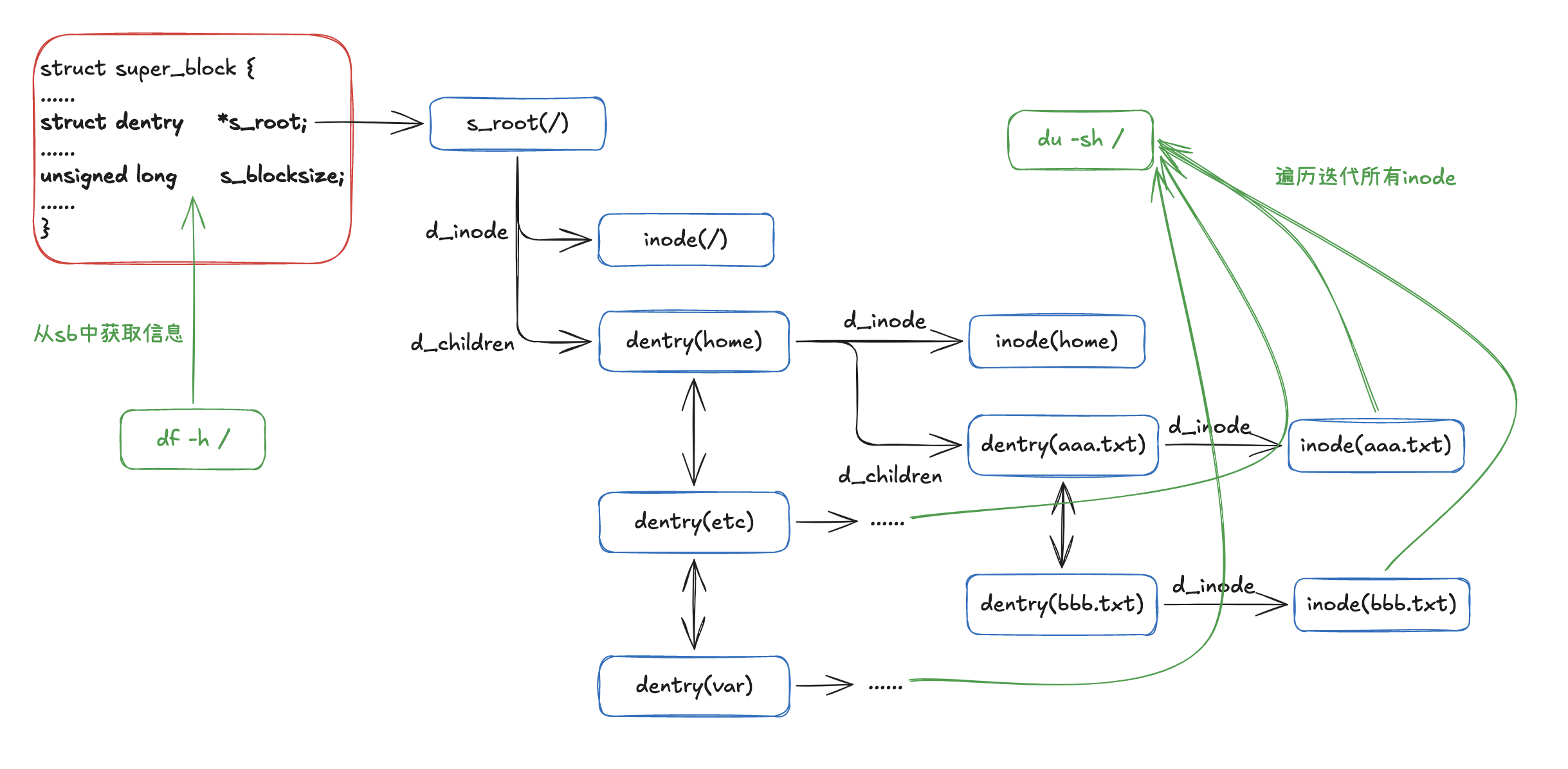
df命令是读取文件系统的sb的信息,而du命令是遍历迭代读取目录下所有的文件。
- rm命令与fd的释放
从实验中可以看到,rm删掉文件并不代表就清除了一切与该文件相关的信息了,至少在某个进程还持有fd的时候,sb中是还统计着这个文件的相关信息的。
这就要看一下rm的过程了,strace看一下,主要的系统调用就是unlinkat
......
newfstatat(AT_FDCWD, "aaa", {st_mode=S_IFREG|0644, st_size=1073741824, ...}, AT_SYMLINK_NOFOLLOW) = 0
unlinkat(AT_FDCWD, "aaa", 0) = 0
lseek(0, 0, SEEK_CUR) = -1 ESPIPE (Illegal seek)
close(0) = 0
......
看一下unlinkat的主要实现流程:
unlinkat系统调用
->filename_rmdir //用于删除目录
->filename_unlinkat //删除文件
->start_dirop //获取锁相关、获取dentry等
->ihold(inode) //hold一下,防止操作期间被其他地方释放?
->vfs_unlink
->ext4_unlink
->__ext4_unlink
->ext4_delete_entry //删除对应的dentry
->drop_nlink //inode的__i_nlink计数减1(如果减到0了,就标记为孤儿inode)
->end_dirop
->iput(inode)
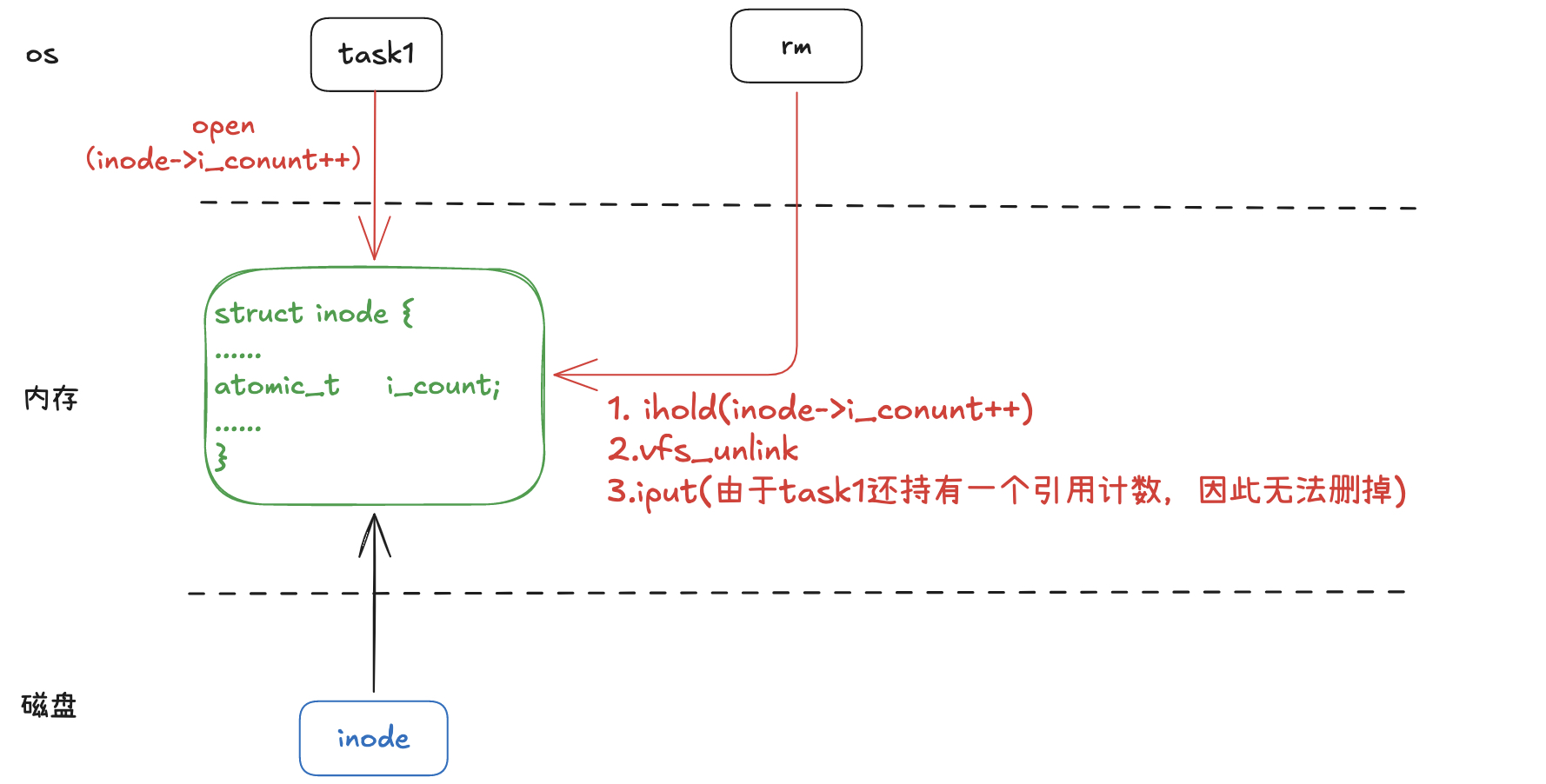
看一下iput的实现:
void iput(struct inode *inode)
{
might_sleep();
if (unlikely(!inode))
return;
......
//如果inode的引用计数不是1,则减1继续执行。如果不是1,就减1并return
if (atomic_add_unless(&inode->i_count, -1, 1))
return;
所以过程就已经很明显了:inode的释放实际上是在iput判断inode的i_count引用计数为1(减1之后变为0)的情况下才去真正地执行删除inode相关操作的。如果没有进程持有fd的情况下,rm命令执行结束后会有一次iput操作,这里可以删掉inode。但是如果有进程持有inode引用计数的情况下,rm的iput将只是减少引用计数并不能删除inode,除非等持有inode引用计数的进程自己释放fd的时候调用iput删除。
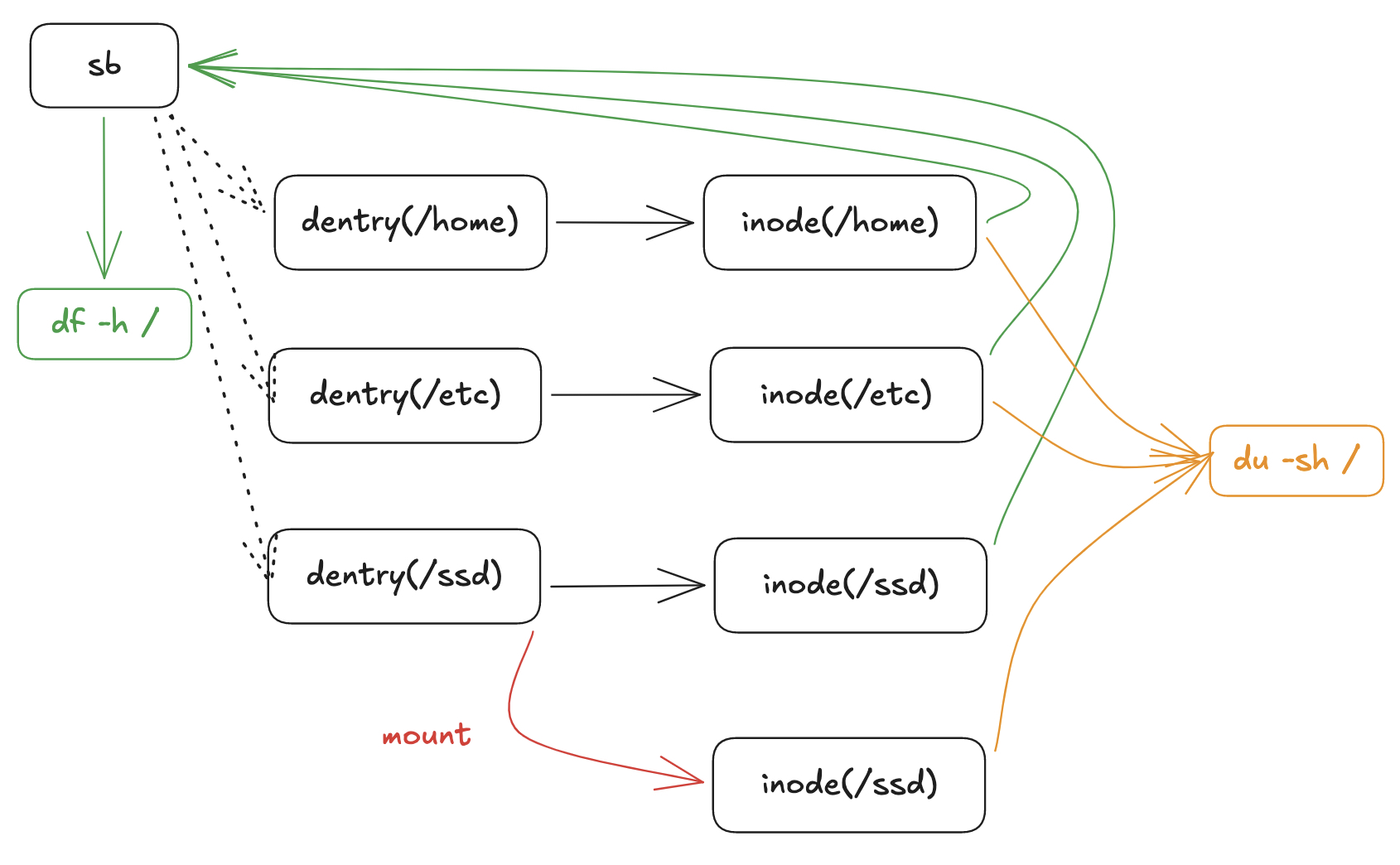
- 为什么挂载点覆盖会导致df和du命令显示的磁盘容量不一致?
这个其实也好解释了:/ssd下原本就是有内容的,这个在当前的sb中是记录了的。然而,没有把当前目录下的内容清空就mount到了nvme盘上,这样的话,/ssd的dentry应该就指向一个新的inode了,这个新的inode就是这个新挂载的文件系统的根节点。df命令直接去找sb中的信息进行计算,未挂载前的/ssd中是有内容的切并没有释放,所以在df命令中是能够统计出来的。而du命令是通过遍历所有dentry去找inode的信息并综合计算的,当前的/ssd的dentry已经指向了新的inode,所以自然计算结果与df的不符合了。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 857879363@qq.com