问题
近期遇到一起mlx网卡分sf失败的问题。
本人对mlx驱动中sf的分配过程并没有详细研究过,因此借助大模型完成了这个问题的定位与修复。在此记录一下这个过程。
背景知识
让大模型先帮我总结了一下pf、vf和sf的区别。
PCIe 设备中的 PF、VF、SF 是 I/O 虚拟化中的核心概念。简单来说:
- PF:设备的“大管家”,负责全局管理。
- VF:由 PF 切出的“轻量级分身”,适合直接分配给虚拟机。
- SF:一种更灵活的“轻量级功能单元”,旨在解决 VF 在大规模场景下的局限性。
下面的表格可以帮你更直观地理解它们的区别:
| 特性 | PF (Physical Function, 物理功能) | VF (Virtual Function, 虚拟功能) | SF (Scalable/Sub Function, 可扩展功能) |
|---|---|---|---|
| 本质 | 一个完整、独立的 PCIe 设备 | 主 PF 的轻量级“分身”,共享硬件资源 | 从父设备上切出来的“一部分能力”,更接近于软件定义 |
| 核心功能 | 管理与控制整个设备,如配置、创建 VF | 数据转发与I/O 处理,通常不参与管理 | 数据转发,支持动态创建与销毁,并可拥有部分专属资源 |
| 所需驱动 | 需要完整的、具备管理能力的驱动程序 | 仅需要简单的、进行数据处理的“轻量级”驱动 | 通常复用现有设备驱动模型,管理更依赖软件 |
| 典型应用 | 主机操作系统(如 Hypervisor)使用,管理硬件并创建 VF | 直接分配给虚拟机 (VM) 或容器,实现高性能网络 | 云数据中心、SmartNIC、容器化环境,追求高密度和快速弹性伸缩 |
在mlx5驱动中,ctl irq (Control Interrupt) 和 comp irq (Completion Interrupt) 分别是用于控制平面(如设备命令)和数据平面(数据包收发完成)的两类硬件中断。
它们的核心区别在于功能定位与优化目标:
| 特性 | ctl irq (控制中断) | comp irq (完成中断) |
|---|---|---|
| 中文别称 | 控制中断、异步事件中断 (Async EQ) | 完成中断、数据通路中断 (Completion EQ) |
| 主要用途 | 处理设备的管理平面事件,如:命令完成通知、设备状态变更、错误报告等 | 处理数据平面事件,即高速网络数据包(发送/接收)的完成通知 |
| 性能特点 | 事件频率低,延迟敏感性不高 | 事件频率极高,是网络吞吐和延迟的关键路径,对性能要求极高 |
| 硬件映射 | 使用MSI-X向量表中的一个专用向量,通常会被分配在向量表的特定位置(如最开始或最后) | 使用MSI-X向量表中除控制中断外的多个向量,实现多队列并行处理,提升性能 |
| 驱动设计 | 专门由mlx5_ctrl_irq_request()API申请 |
由通用mlx5_irq_request()API申请,但驱动内部会进行区分和专门优化 |
| 中断处理 | 触发mlx5_eq_async_int(),主要处理异步事件 |
触发mlx5_eq_comp_int(),核心处理数据路径完成事件 |
问题排查
基本的背景知识我们清楚了,接下来就开始问题排查。
先看一下分配vf失败时候的栈:
[39236794.852198] mlx5_core.sf mlx5_core.sf.3: Rate limit: 127 rates are supported, range: 0Mbps to 97656Mbps
[39236794.852830] mlx5_core 0000:0e:00.0: mlx5_irq_affinity_request:140:(pid 3058156): Didn't find a matching IRQ. err= -87
[39236794.852833] mlx5_core.sf mlx5_core.sf.3:mlx5_eq_table_create:1252:(pid 3058156): Failed to create async EQs
[39236794.852834] mlx5_core.sf mlx5_core.sf.3: mlx5_load:1649:(pid 3058156): Failed to create EQs
[39236795.304686] mlx5_core.sf mlx5_core.sf.3: mlx5_sf_dev_probe:69:(pid 3058156): mlx5_init_one err=-87
[39236795.304784] mlx5_core.sf: probe of mlx5_core.sf.3 failed with error -87
看log,我们找到对应的出错的mlx5_irq_affinity_request函数
struct mlx5_irq *
mlx5_irq_affinity_request(struct mlx5_core_dev *dev, struct mlx5_irq_pool *pool,
struct irq_affinity_desc *af_desc)
{
struct mlx5_irq *least_loaded_irq, *new_irq;
int ret;
mutex_lock(&pool->lock);
least_loaded_irq = irq_pool_find_least_loaded(pool, &af_desc->mask);
if (least_loaded_irq &&
mlx5_irq_read_locked(least_loaded_irq) < pool->min_threshold)
goto out;
/* We didn't find an IRQ with less than min_thres, try to allocate a new IRQ */
new_irq = irq_pool_request_irq(pool, af_desc);
if (IS_ERR(new_irq)) {
if (!least_loaded_irq) {
//这里err日志在dmesg只是打印了出来的
/* We failed to create an IRQ and we didn't find an IRQ */
mlx5_core_err(pool->dev, "Didn't find a matching IRQ. err = %pe\n",
new_irq);
mutex_unlock(&pool->lock);
return new_irq;
}
/* We failed to create a new IRQ for the requested affinity,
* sharing existing IRQ.
*/
goto out;
}
.......
看上面这段代码可以轻易知道,肯定是irq_pool_request_irq申请失败了。而且least_loaded_irq也是NULL,所以才能走到这里
但是这里返回的-87是为什么呢?我追踪了irq_pool_request_irq里的函数,发现并没有会返回-87的地方
原来,-87这里是一个乌龙,我查看的是上游的最新的mlx驱动代码,而出问题的内核版本是比较老的,mlx驱动也比较老,其实是应该挂在了这里
static struct mlx5_irq *
irq_pool_request_irq(struct mlx5_irq_pool *pool, const struct cpumask *req_mask)
{
cpumask_var_t auto_mask;
struct mlx5_irq *irq;
u32 irq_index;
int err;
if (!zalloc_cpumask_var(&auto_mask, GFP_KERNEL))
return ERR_PTR(-ENOMEM);
err = xa_alloc(&pool->irqs, &irq_index, NULL, pool->xa_num_irqs, GFP_KERNEL);
if (err) {
if (err == -EBUSY)
err = -EUSERS;
return ERR_PTR(err);
}
.......
#define EUSERS 87 /* Too many users */
这里从irq pool中申请irq的时候,xa_alloc失败会返回EBUSY,而旧驱动里会把EBUSY改成EUSERS,EUSERS的错误码正是87
然后这时候检查基础环境发现了一点异常,这台机器有一部分的核被offline了
所以猜测就是因为关核导致了最后的分sf异常
然而,添加一些debug日志之后,我发现:无论是否关核,irq_pool_request_irq其实都是失败的。
也就是,问题的根因在于,关核之后,least_loaded_irq变成NULL了。添加debug日志测试之后发现确实如此。
继续添加更多的debug日志之后发现了问题:mlx驱动使用irq_pool_find_least_loaded这个函数去找一个已经load的irq用于共享,在cpumask_subset中,原本req_mask是cpu_online_mask(没有offline之前的),而iter_mask是offline之后的cpumask,这就导致这个cpumask_subset判断子集失败了,因此irq_pool_find_least_loaded返回为NULL了。
static struct mlx5_irq *
irq_pool_find_least_loaded(struct mlx5_irq_pool *pool, const struct cpumask *req_mask)
{
int start = pool->xa_num_irqs.min;
int end = pool->xa_num_irqs.max;
struct mlx5_irq *irq = NULL;
struct mlx5_irq *iter;
int irq_refcount = 0;
unsigned long index;
lockdep_assert_held(&pool->lock);
xa_for_each_range(&pool->irqs, index, iter, start, end) {
struct cpumask *iter_mask = mlx5_irq_get_affinity_mask(iter);
int iter_refcount = mlx5_irq_read_locked(iter);
if (!cpumask_subset(iter_mask, req_mask))
/* skip IRQs with a mask which is not subset of req_mask */
continue;
if (iter_refcount < pool->min_threshold)
/* If we found an IRQ with less than min_thres, return it */
return iter;
if (!irq || iter_refcount < irq_refcount) {
/* In case we won't find an IRQ with less than min_thres,
* keep a pointer to the least used IRQ
*/
irq_refcount = iter_refcount;
irq = iter;
}
}
return irq;
}
问题深究
以上我们其实已经定位出了问题产生的直接原因,但是还有一些问题并没有澄清。整个问题发生的流程是什么样的,问题根因是什么?为什么vf不会出现这样的问题呢?
我们直接追一下分sf的流程,从probe驱动开始:可以看到,sf驱动probe的过程中,在执行mlx5_irq_table_create的时候,如果判断到这是一个sf,就直接跳过irq_table的创建,然后继续执行mlx5_eq_table_create去创建eq table,在这里最终会调用到导致失败的mlx5_irq_affinity_request函数。
mlx5_sf_dev_probe
->mlx5_init_one
->mlx5_load
->mlx5_irq_table_create
->mlx5_eq_table_create
int mlx5_irq_table_create(struct mlx5_core_dev *dev)
{
int num_eqs = mlx5_max_eq_cap_get(dev);
bool dynamic_vec;
int total_vec;
int pcif_vec;
int req_vec;
int err;
int n;
if (mlx5_core_is_sf(dev))
return 0;
.......
//sf在mlx5_irq_table_create中跳过了irq table的创建,然后继续执行mlx5_eq_table_create
mlx5_eq_table_create
->create_async_eqs
->mlx5_ctrl_irq_request
->mlx5_irq_affinity_request
那么为什么创建sf时要跳过irq table的创建呢,是那一步导致最终出现问题呢?
我们来详细分析一下mlx5_ctrl_irq_request这个函数,这个函数主要是给mlx5设备申请一个ctl irq。函数逻辑很清晰。大体执行过程为:获取设备对应的irq pool,分配一个irq_affinity_desc结构体,给他的mask赋值为当前的online cpu mask,因为是sf,所以去执行mlx5_irq_affinity_request申请一个irq,这个irq必须要在af_desc内的,也就是必须指向当前的online cpu mask的。
继续看,可以找到出现问题时候的代码,执行mlx5_irq_affinity_request去申请irq,这里想要调用irq_pool_find_least_loaded从irq pool中去找到一个可用的irq,但是失败了。
/**
* mlx5_ctrl_irq_request - request a ctrl IRQ for mlx5 device.
* @dev: mlx5 device that requesting the IRQ.
*
* This function returns a pointer to IRQ, or ERR_PTR in case of error.
*/
struct mlx5_irq *mlx5_ctrl_irq_request(struct mlx5_core_dev *dev)
{
struct mlx5_irq_pool *pool = ctrl_irq_pool_get(dev);
struct irq_affinity_desc *af_desc;
struct mlx5_irq *irq;
af_desc = kvzalloc_obj(*af_desc);
if (!af_desc)
return ERR_PTR(-ENOMEM);
cpumask_copy(&af_desc->mask, cpu_online_mask);
af_desc->is_managed = false;
if (!mlx5_irq_pool_is_sf_pool(pool)) {
/* In case we are allocating a control IRQ from a pci device's pool.
* This can happen also for a SF if the SFs pool is empty.
*/
if (!pool->xa_num_irqs.max) {
cpumask_clear(&af_desc->mask);
/* In case we only have a single IRQ for PF/VF */
cpumask_set_cpu(cpumask_first(cpu_online_mask), &af_desc->mask);
}
/* Allocate the IRQ in index 0. The vector was already allocated */
irq = irq_pool_request_vector(pool, 0, af_desc, NULL);
} else {
irq = mlx5_irq_affinity_request(dev, pool, af_desc);
}
kvfree(af_desc);
return irq;
}
struct mlx5_irq *
mlx5_irq_affinity_request(struct mlx5_core_dev *dev, struct mlx5_irq_pool *pool,
struct irq_affinity_desc *af_desc)
{
struct mlx5_irq *least_loaded_irq, *new_irq;
int ret;
mutex_lock(&pool->lock);
least_loaded_irq = irq_pool_find_least_loaded(pool, &af_desc->mask);
......
static struct mlx5_irq *
irq_pool_find_least_loaded(struct mlx5_irq_pool *pool, const struct cpumask *req_mask)
{
int start = pool->xa_num_irqs.min;
int end = pool->xa_num_irqs.max;
struct mlx5_irq *irq = NULL;
struct mlx5_irq *iter;
int irq_refcount = 0;
unsigned long index;
lockdep_assert_held(&pool->lock);
xa_for_each_range(&pool->irqs, index, iter, start, end) {
struct cpumask *iter_mask = mlx5_irq_get_affinity_mask(iter);
int iter_refcount = mlx5_irq_read_locked(iter);
if (!cpumask_subset(iter_mask, req_mask))
/* skip IRQs with a mask which is not subset of req_mask */
continue;
......
所以就要看一下ctrl_irq_pool_get获取的irq pool是从哪来的?从下面这几个函数就可以看出来,如果是sf的话,返回的是他的parent这里也就是pf的irq_table,然后返回的是pf的irq_table中的sf_ctrl_pool作为这个sf的irq pool。
static struct mlx5_irq_pool *ctrl_irq_pool_get(struct mlx5_core_dev *dev)
{
struct mlx5_irq_table *irq_table = mlx5_irq_table_get(dev);
struct mlx5_irq_pool *pool = NULL;
if (mlx5_core_is_sf(dev))
pool = sf_ctrl_irq_pool_get(irq_table);
/* In some configs, there won't be a pool of SFs IRQs. Hence, returning
* the PF IRQs pool in case the SF pool doesn't exist.
*/
return pool ? pool : irq_table->pcif_pool;
}
struct mlx5_irq_table *mlx5_irq_table_get(struct mlx5_core_dev *dev)
{
#ifdef CONFIG_MLX5_SF
if (mlx5_core_is_sf(dev))
return dev->priv.parent_mdev->priv.irq_table;
#endif
return dev->priv.irq_table;
}
static struct mlx5_irq_pool *sf_ctrl_irq_pool_get(struct mlx5_irq_table *irq_table)
{
return irq_table->sf_ctrl_pool;
}
所以我们就看一下pf的sf_ctrl_pool是什么时候创建的?这里可以看到,pf的sf_ctrl_pool是在probe mlx5驱动的时候就申请内存并初始化的,这里只是把sf_ctrl_pool这个irq pool给初始化了,并没有去实际的申请irq。
mlx5_core_driver->probe
->probe_one
->mlx5_init_one
->mlx5_init_one_devl_locked
->mlx5_load
->mlx5_irq_table_create
->irq_pools_init
static int irq_pools_init(struct mlx5_core_dev *dev, int sf_vec, int pcif_vec,
bool dynamic_vec)
{
......
/* init sf_ctrl_pool */
num_sf_ctrl = DIV_ROUND_UP(mlx5_sf_max_functions(dev),
MLX5_SFS_PER_CTRL_IRQ);
num_sf_ctrl = min_t(int, MLX5_IRQ_CTRL_SF_MAX, num_sf_ctrl);
if (!dynamic_vec && (num_sf_ctrl + 1) > sf_vec_available) {
mlx5_core_dbg(dev,
"Not enough IRQs for SFs control and completion pool, required=%d avail=%d\n",
num_sf_ctrl + 1, sf_vec_available);
return 0;
}
table->sf_ctrl_pool = irq_pool_alloc(dev, pcif_vec, num_sf_ctrl,
"mlx5_sf_ctrl",
MLX5_EQ_SHARE_IRQ_MIN_CTRL,
MLX5_EQ_SHARE_IRQ_MAX_CTRL);
真正的irq申请,是在sf初始化的时候。
所以,事情到这里已经就非常清晰明了了,出现问题的过程应该是:
1.系统启动,probe mlx5驱动,创建sf_ctrl_pool。
2.请求创建sf,从sf_ctrl_pool中申请一个irq,这个irq的mask是当前的cpu_online_mask,假设是{0-191}。
3.把当前系统中的某个cpu offline,假设offline 20号cpu。
4.再次申请创建一个sf,调用mlx5_irq_affinity_request尝试申请一个irq,使用的af_desc->cpumask是现在的cpu_online_mask,即{0-19,21-191},尝试去按照这个afdesc->cpumask去申请irq,irq_pool_find_least_loaded会遍历当前sf_ctrl_pool中的所有irq,先检查遍历的irq的cpumask是不是af_desc->cpumask的子集。很明显,在offline一个cpu之后,sf_ctrl_pool中的irq cpumask并不是其子集,因此不会使用。
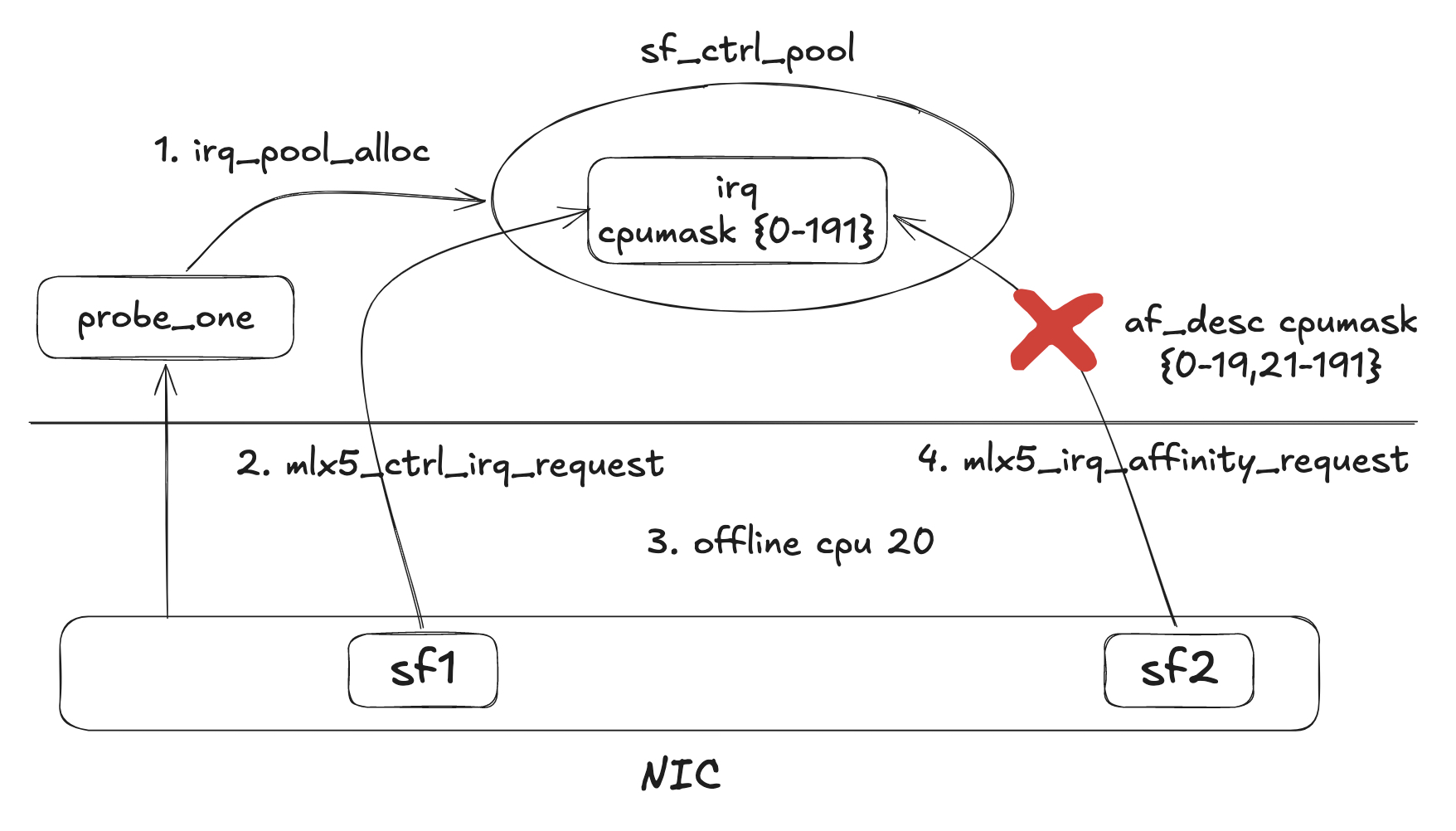
那么vf为什么没有这个问题呢?因为vf有自己的pci_dev,不使用pf的irq table,vf之间也不像sf一样共享ctl irq。
问题修复
了解了问题产生的根因,问题修复也就显而易见了,只要遍历sf_ctrl_pool中的irq时使用他真正指向的cpumask去判断子集即可,而不是使用irq->mask。
--- a/drivers/net/ethernet/mellanox/mlx5/core/irq_affinity.c
+++ b/drivers/net/ethernet/mellanox/mlx5/core/irq_affinity.c
@@ -105,9 +105,12 @@ irq_pool_find_least_loaded(struct mlx5_irq_pool *pool, const struct cpumask *req
lockdep_assert_held(&pool->lock);
xa_for_each_range(&pool->irqs, index, iter, start, end) {
- struct cpumask *iter_mask = mlx5_irq_get_affinity_mask(iter);
int iter_refcount = mlx5_irq_read_locked(iter);
+ const struct cpumask *iter_mask;
+ iter_mask = irq_get_effective_affinity_mask(mlx5_irq_get_irq(iter));
+ if (!iter_mask)
+ continue;
if (!cpumask_subset(iter_mask, req_mask))
/* skip IRQs with a mask which is not subset of req_mask */
continue;
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 857879363@qq.com